Over the past two years, I analyzed with a couple of colleagues how we judge how much quality is “good enough”. Such a statement is usually an outcome of a discussion and a consent that needs to be found on every different project and every different company.
It is also quite different, depending on your product life cycle. This talk starts with this “balance” of how-much-quality you need and investigates how this knowledge can be taken into the interactions of you and other people in the team.
For the entertainment part, it’s wrapped into an cheesy story about ancient gods and titans – arguably a bit too cheesy 😉
or: The business value of “being agile & innovative”
This is the talk that I gave together with Jana at the EdgeX Conference.
MOIA faced a radical changing market environment, when Covid hit Hamburg and no one was allowed to ride a MOIA anymore. But what do you do in your company and in your team if giving up is not an option? With crisis-after-crises in the past years, the flexibility to adhere to changing markets on a company- to team-level became a true asset.
The basic idea behind “being agile” was that companies and businesses should be flexible enough to react to changing market requirements. It also describes the evolutionary processes inside a single team: As smaller business units, also teams need some flexibility to adopt to those changing markets conditions and to be able to unleash their full innovative potential.
Listen to Finn and Jana who will tell you the story of MOIA and how daring can innovate not only a product but also a company with a truly #agile reaction to new needs of the market.
“Director of Engineering” / DOE. What does that actually mean? What does it mean in the specific context of the company I work for, MOIA? And in the context of who I am, Finn? With my strength, my weaknesses, my education and my past experiences?
I am in the Role of the DOE for 20 months now. Good enough a reason to reflect on the journey until now.
How did it change my view on “Leadership”?
How did it change my view on teams?
And how did it change my view upon myself?
Find those three reflections in the three sections below.
Leadership
I like servant leadership. Some people also call it host leadership. And maybe the second expression fits even better to me. If I am host to a party, I invite a lot of people. I host them and welcome them when they arrive. I am typically not their servant. Instead, I make them feel comfortable and see to their needs. I try to accomplish something (a party) by connecting people and make sure they have a good time.
If you ask leaders, especially in modern Product- / Software-Development, I would dare to say that 90% of people would attest to themselves that they are servant leaders, that they are not micro managing teams. When people ask me, I do state the same. However, despite good intentions a lot of people are micro managing, certainly waaaaaay more than the other 10%. “Managers” are interfering with daily tasks of teams or team members. Managers are telling teams and people what to do and how. So, am I part of a group having a wrong self-assessment?
Looking into Wikipedia, I find:
In business management, micro management is a management style whereby a manager closely observes and/or controls and/or reminds the work of their subordinates or employees.
If I translate that to the software building teams, then I would state:
A micro manager is a person, who closely observes and/or controls and/or reminds the work of a team.
If I want to ensure a servant leadership style, I must work hard to not closely observe the work of the team. I shall certainly not control their work nor remind them what to do. Hence, I have to: look away, have a loose contact with the team and when I see something is forgotten: not remind them.
That is sometimes really hard.
I am not just a DOE. I am also a person with 10+ years of experience improving the quality of the software and entire product a team is contributing to. And I do know for a fact that there are a couple of points, where the teams I work with can improve, in parts significantly. The problem is: if I “go into details” ( = closely observe ) and start to coach teams “hands-on” how they can accomplish a certain thing better ( = control ) and “iterate” with them on it ( = remind), then I am the very definition of a micro manager. Huh.
So, what to do instead? As a first simple approximation: Training and/or Empowerment.
Sometimes people know how to work smarter, they just do not feel a mandate to spread the word and go change the world (or their team’s process, if not the world). If I am lucky, they share their idea in a random water cooler conversation or scheduled 1:1. For that case, the matter is rather simple: I can offer my knowledge and support in individual coaching and mentoring and encourage / empower the person to “Go. Do it!”.
However, if people and teams are not aware of the room to improve… then the only lever I have is to influence them = to give them structure and culture. And both things take a long time. “Giving structure” relates to the roles we have and how they collaborate. What leaderships roles do we need in the team? Who is responsible for what? How shall those abstract roles communicate and interact with each other? I can then postulate an abstract model and hope (fingers crossed!) that many or most or maybe-maybe all teams interpret it in the right way and actually do it. Structure set.
Afterwards, I can offer trainings. With recommendations how to approach an abstract problem or generic situation. How to write stories. How to conduct event stormings. How to create story- and service maps. How to take full days for occasional team alignments before the next-big-thing on the roadmap comes. And then I can hope (fingers crossed!) that many or most or maybe-maybe all teams interpret it in the right way and actually do it. Culture set.
I just need to be sure to build something resilient, yet flexible for our business model into culture and structure. If both is too weak it will topple and create chaos on the next stress point. If it is too rigid, we loose our ability to adopt.
All of this led for me to the interesting revelation, that I sometimes have to not help a team or make a decision for them, even if they want it. I would, upon request, become their micro manager. Which, in the long run, does not serve the team, the product or the entire company.
20 months into this journey, I got the ropes a bit. I failed, too. But I hope to learn. If there is one recommendation I can give, it is a quote from a character in a 60 year old novel:
Give as few orders as possible. Once you’ve given orders on a subject, you must always give orders on that subject.
Leto Atreides
In conclusion, it means that if you have to look away, have a loose contact with a team and when you see something is forgotten: not remind them, then you mostly have to deal with yourself: with the unease in your chest. You have to let go of control. You have to fully submerge into trusting many people you maybe do not even really know. And then wait and see and observe wonderful things to happen.
Teams
Autonomous Teams for the win!
I studied physics. And back then, in the working group where I was, the two professors gave all folks full autonomy on conducting experiments, measuring, improving and – obviously – writing their own theses. On the one hand I learned to motivate myself towards an abstract goal early on and work towards it autonomously, also without external pressure. On the other hand, I learned to value managing priorities, time, workload and work packages myself.
After studying I started to work in a startup that was way too chaotic that anyone would have started to manage my work directly (see part of the tech department in the picture above). And then I joined a consultancy that specialised on building autonomous product- and delivery focused teams. One could say that I got a really great education on the values of autonomous teams that decide for themselves, how they fulfill certain requirements and/or business goals. What became tedious for me in the previous company was to always work on an autonomous team and setup from my traditional QA Role. On top of that, once we got a desired autonomous-teams setup into place, naturally, my impact or contribution was limited to this single one team.
With the move into the DOE-Role, I finally had the chance to just give this autonomy to teams without them having to convince me of it. How cool was that?
Rather than giving specific lists of tasks […], I gave broad guidance and told them to prepare the task lists and present the lists to me. Rather than telling everyone what we needed to do, I would ask questions about how they thought we should approach the problem. Rather than being the central hub coordinating maintenance between two [teams], I told the [team leads] to talk to each other directly.
Things did not go well.
L. David Marquet – Turn the ship around!
The very same thing was true for me. What I failed to realise was, that not all teams and people where ready for this. In fact, in one team I lost two Backend-Developer over it. Later, I had an explicit conversation with the Technical Lead in this team about the issue. The person shared that they and, by extension, the team never understood the tasks they should do with the open questions that I asked. They shared their frustration of how hard it was to always interpret my questions so that they could derive the ToDos for them. How tedious it was to collect my exact expectations of how to conduct a specific task.
That was very eye-opening and a true learning for me. After taking some time to talk about it, we were able to resolve this “small” 😉 missunderstanding. The Technical Lead – and by extend – the entire team afterwards took more ownership over their roadmap, their technical debt – and a meaningful way to combine the two things into a sensible roadmap. Autonomously. Empowered.
I learned yet again how important explicit expectation setting is, even if you only give room and space for people (and do not restrict it). Since if they are not aware they can walk into this room, it may very well be, they never will.
Looking at the teams I work with now, I believe we are all setup to embark with an autonomous setup. Which is the true hard requirement to creatively build a society-disrupting fancy new technology.
Myself
Sometimes, I feel lonely. Sometimes, I feel frustrated. The quality of Feedback that I get went down once the word “Director” moved into the title of my role description. Apart from my peers, there are very few people in the organisation that (still) give me true feedback. Constructive feedback, the difficult stuff. I am very grateful to them. Amongst other, this is especially a shout out to Stef, Roza, Julez, Alina, Roya and Laurita. Thank you, for your candid and helpful feedbacks. They are the foundation for the growth that I still hope to experience ♥
Interestingly, while I get less feedback and less often, people obviously expect me to reflect even more than everyone else on every word or sentence, eye-contact or other day-to-day interaction that I write, have or do. It took me a while to realise that this is not my personal experience but part of “becoming a leader”. That is a part of what I, as anyone else, have to cope with. And the only way to “mitigate” the lack of feedback is indeed to reflect more and deeper than before. To no real surprise, this leads to actually gain a better understanding of ones strength and ones “learning opportunities” (a.k.a. weaknesses).
I am energetic. And positive. And I inspire people. Apparently. I never interacted with myself. It is hard to understand how a group of 50 people observes and actually sees me in a remote meeting (with 20 cameras off) when I share something. Being “energetic” is typically associated positive and seen as a strength. Unless people feel a pressure to behave the same way. I learned to walk this line a lot more careful than in the past. I also learned to share in which context people should understand something that I say. Do I give advise, recommendations or do I want people to do specific things in a specific order? (mostly it is one of the first two) I take more time for it now, which in turn leads to some people being annoyed by my constant disclaimers. Well…, there still is some learning opportunity for me, I would say. 🙂
But then also, I want my kids to not have to do a driver license. I want our society to advance to a point in their mobility where no one does driver licenses any more. Where we do not need to privately own a car- and by extend have to occupy public spaces with those huge chunks of metal. And I know, I learned, that I can have a much larger impact in a position that scales across teams. Which enables others. Where people are empowered and trusted. Hence, I am in fact truly motivated to continue my current journey. To do the very best that I can in the role I am currently playing. I will do everything to the extend of my skills and abilities, with the knowledge at hand to make my vision, MOIAs Vision, become reality. It is not yet time to rest 🙂
I joined my previous employer, ThoughtWorks, round about 6 years ago. It has been a fantastic journey. I can certainly say that the vibrant (and a bit chaotic) environment helped me, to again and again become a better version of myself. I got an incredible amount of feedback from many different people with vast experience in many different fields of “technology”. This was a key enabler for me over the past years.
I joined ThoughtWorks to improve my “QA Engineering” skill, especially in End-To-End Test Automation. And uhh… how much did I have to learn! Thanks to Dani, Mario, Nadine and Robert (who were the QAs at ThoughtWorks when I joined), I quickly discovered that the scope in which you can increase the level of quality was massive. So much more than I could have imagined before.
I joined Otto as my first project and many more followed. I gathered experience in 15 different teams over the course of those 6 years. They distributed across all kinds of tech stacks, domains, companies, projects, locations… One thing was always the same though: all teams had errors in the software. Since starting my career I’ve seen all kinds of Data Storage (SQL, PostgreSQL, MariaDB, CouchDB, MongoDB, Cassandra, Redis, Elastic Search, Splunk, DynamoDB, S3, …) and worked with all kinds of Programming Languages (Turbo Pascal, Fortran, C++, Ruby/Rails, Javascript, Swift, Java, Clojure, Kolin, Scala, Typescript, …). However, regardless of the technology in use, there were always errors.
And isn’t that odd? Let me repeat that last part: “Regardless of the technology in use …”. That would mean that the technology is not the problem. And since we already make errors when we use technology to solve errors in the real world, let me suggest to not only rely on technology to solve errors in technology. The conclusion, however, is that we should take a step back from “test-automation-everything” and admire the core problem a bit longer. And ultimatley, it is easy to spot: The one common denominator, the one factor which contributed to errors in all those systems is us – us Humans.
Whoever worked with me in the past years will have noticed, that I started to focus not only on the technological part and some kind of governance ( = “the process” ), but to equally look into team dynamics. And to understand how information is transported through the team. How requirements were very clear to everyone – or more often not. Using Conway’s law in reverse, I am trying to build teams that resemble a high quality human-interaction so that their services and software display this very same attribute. The only way to build teams in this way, is to make “Quality” (for whatever “Quality” means in detail for a specific context) an integral part of a team’s culture.
The problem is, that it is difficult to map a job with the Title “team culture enablement to improve the Quality of Software-Products using Convey’s law in reverse” into the QA career path of a high performing global cutting-edge technology consultancy 🙂 In the beginning of my employment with ThoughtWorks, it was a great journey, as a QA, since the environment allowed me to “shift left” and “shift right” and “deep dive” in my role. All at the same time! I am very grateful for this opportunity that was given to me. I am thankful for the room, my colleagues gave to me. I hope I could also deliver on their expectations!
However, the further my journey took me, the more I noticed how limited a “QA Role” was defined for the clients I worked with. Hence, for every new project I had to emancipate from the initial client’s role understanding and evolve this together with the client in a positive and constructive way. After some time, even this small cultural transformation becomes repetitive and then tedious.
But it must have been fate: At some point I joined a client organization, where there were many interesting and wild thoughts in those directions around “Quality”. It was a Hamburg Startup. The Name of this company is MOIA.
However, before I dive into the specifics of MOIA, I have to do the unavoidable detour for a bit of context setting: I joined the MOIA-project about half a year before the Corona Virus hit us. Once we were in the middle of the pandemic, my family reflected how we wanted to shape our future and whether we see this future in a world-famous metropolis or – and this is what we ultimately decided for – rather in the country side. Hence, we shifted gears and started to look for a new home in a small village in the middle of Schleswig-Holstein. The aspect of more Home-Office obviously contributed to paint this picture of our family-future. With Moia having the majority of their tech development in Hamburg, it was a perfect match to shape a new path forward ❤
By the time that we concluded our family plans, I had also established deeper connections (I want to say: roots!!) within MOIA. Back in the days of the first Corona wave, I worked with one of the best and most empathetic teams I ever had the pleasure to work with. And all of those fine folks were from MOIA! Besides, the current set of challenges is extremely interesting: a distributed system of many services and apps and web technologies. And a great demand on Quality for the end product. However, in many places the bi-weekly releases are still served with big amounts of manual regression testing. What a Shocker! Someone needs to do something about this! And I want to believe that those are areas, where I can contirbute to.
And the best thing is: The company has an amazing culture of trustful and constructive collaboration. New ideas are welcome and (sometimes more, sometimes less) enthusiastically implemented 🙂 Appreciation is given towards each other freely and frequently.
Furthermore, MOIA is a company with a great Vision. MOIA participates on the endeavour to change our cities, to very actively contribute to one puzzle piece of the “Verkehrswende” (= transformation ofmobility and transportation in Germany). I found a role where I can contribute to the culture of many teams and still have a direct impact on the Quality, the processes around it and the Strategies and Approaches (and also to testing throughout the entire company). This is a huge, difficult and quite complex task.
I am looking forward to truly immerse myself into this task, to really and wholeheartedly fall in Love with the Product that I am am helping to build. To continue to work with great people that I’ve met over the last two years and to contribute to shape a future for MOIA and our cities. And to plant some seeds in a company culture. To grow them and to cater to their needs for many years – and not months.
I am grateful for my journey up until now, which brought me to this point. My thanks go to all the people who contributed to the experiences that I have and who definitely had their share in making me the person that I am.
Yes, I am a Trekkie. And while I usually do not share such stuff it is the little bit of context setting I need for this blog post.
Since everyone moved to their home offices in the wake of corona, our team put some deliberate effort into their ceremonies, to make them something “special”, to compensate for not meeting IRL any more. Thus, I had the honor to design our first online retro. I received fantastic feedback, thus I thought it may be quite interesting for others to try something like this, too.
The Format
I chose a format that I call 2 : 4 : 8 (I believe I found this label somewhere else, but unfortunately, I wasn’t able to dig it up and link to it again).
The idea of the format is the following: In normal Retros there are up to 10 devs and 2 – 3 other roles. Due to the nature of the roles, also a lot of tech problems are usually shared. In the democratic dot-voting afterwards, the developers often promote the tech topics. I am not saying that this is bad intention, it’s just a natural outcome based on the interests of the different groups in a retro.
To avoid this effect, we went for a format which supports “minorities” and focuses on how important a topic to a certain person is. In this format usually topics come up that are super important to some people but can in the other format never be shared other than in a side note. It’s a very inclusive retro edition.
Here is how it works:
each person writes down what the two most important things are to them. There is no categorization: could be things to start or stop or change or …, there is just limitation that it could only be 2 things in total for each person. (Most retros allow unlimited amounts of contributions but restrict the categories, this was the other way around: unlimited/no categories but restricted to 2 contributions).
after each person found two issues that were most important to them, the participants were paired up. Then, 2 paired-up people need to agree on the most 2 important thing inside their pair. (So 2 people each bring 2 topics = 4 issues in the pair. Then the pair needs to pick the top 2 of them)
after the pairs found two issues they go into group discussion (2 pairs = 4 people now). Again, they should discuss the two most important issues.
finally, all get together with a total of 4 issues left. They are discussed, action items are derived and assigned. Finally, the retro is closed.
The Story
So I wrapped the retro into a Star Trek Story. I used the video conferencing system Zoom which allowed me to share video and audio from my computer. And it allowed me to design “breakout rooms” which I could then assign to the people. This was particularly helpful to have all the different discussions with different amounts of people. I also used google slides as the collaborative tool.
I think one can make it work with any tool and there are tools out there which work even better. This combination was just handy for me and I will use this as the example tool going forward.
Setting the Mood
Before the first people joined, I started my screen sharing with the presentation. The first slide had a video and background music. In this way, the people who joined early had a bit of space themed ambience music while waiting. That was already a positive and freshly surprising start.
After officially starting the retro, we watched a tiny teaser to get into the Star Trek mood:
We followed with a “Weather Check” to see how everyone felt and continued with a “Safety Check” to understand if the level of trust in the Retro was high enough. I used an anonymous google form to collect that data, that was a bit cumbersome to set up but an easy, quick and secure way to collect this information.
After that, we went into the 2 : 4 : 8 exercise: The Google Presentation Deck was shared with all and each person randomly picked a Star Trek movie character and wrote (5 min timebox) 2 things to change or stop or improve.
Then the people were asked to team up. There were prepared zoom breakout rooms in the call with names fitting the theme (“Bridge”, “Captain’s Ready Room”, …). On one slide there was a pre-selection which characters would meet in which room. In this way it was a random meet & mix of people who would share their thoughts.
After the pair discussions, we came back once more and divided into two groups with 4 or 5 people, each. Then both smaller groups reported the two main issues back to the whole group and we discussed actions for them.
This gave us quite some action items for 4 issues we found. It also turned out that no-one in the team (but me) watched Star Trek. However, everyone enjoyed the retro and some said it was “the best they ever had in their live”.
The full slide deck is here as a PDF. This is for inspiration, I don’t think that one could just copy & paste the whole thing.
This is a template for the retro. We were 9 people + me facilitating, thus, this is how it’s structured. The format itself also works for 30 people.
When great thinkers think about problems, they start to see patterns. They look at the problem of people sending each other word-processor files, and then they look at the problem of people sending each other spreadsheets, and they realize that there’s a general pattern: sending files. That’s one level of abstraction already. Then they go up one more level: people send files, but web browsers also “send” requests for web pages. And when you think about it, calling a method on an object is like sending a message to an object! It’s the same thing again! Those are all sending operations, so our clever thinker invents a new, higher, broader abstraction called messaging, but now it’s getting really vague and nobody really knows what they’re talking about any more. Blah.
When you go too far up, abstraction-wise, you run out of oxygen. Sometimes smart thinkers just don’t know when to stop, and they create these absurd, all-encompassing, high-level pictures of the universe that are all good and fine, but don’t actually mean anything at all.
These are the people I call Architecture Astronauts. It’s very hard to get them to write code or design programs, because they won’t stop thinking about Architecture. They’re astronauts because they are above the oxygen level, I don’t know how they’re breathing. They tend to work for really big companies that can afford to have lots of unproductive people with really advanced degrees that don’t contribute to the bottom line.
A recent example illustrates this. Your typical architecture astronaut will take a fact like “Bitcoins are a blockchain service to exchange money anonymiously” and ignore everything but the architecture, thinking it’s interesting because it’s blockchain, completely missing the point that it’s interesting because it allows to exchange money anonymously.
All they’ll talk about is blockchain this, that, and the other thing. Suddenly you have blockchain conferences, blockchain venture capital funds, and even blockchain backlash with the imbecile business journalists dripping with glee as they copy each other’s stories: “Blockchain: Dead!”
The Architecture Astronauts will say things like: “Can you imagine a concept like Bitcoin where you can exchange anything, not just money?” Then they’ll build applications for supply chains that they think are more general than Bitcoin, but which seem to have neglected that wee little feature that lets you send and receive money without giving away your name — the feature we wanted in the first place. Talk about missing the point. If Bitcoins weren’t blockchain but they did let you swap money anonymously, it would have been just as popular.
Another common thing Architecture Astronauts like to do is invent some new architecture and claim it solves something. Kotlin, ProtoBuffer, REST, RabbitMQ, GraphQL, IOT, Micro Services, oh lord I can’t keep up.
I’m not saying there’s anything wrong with these architectures… by no means. They are quite good architectures. What bugs me is the stupendous amount of millennial hype that surrounds them. Remember the Microsoft .NET white paper?
The next generation of the Windows desktop platform supports productivity, creativity, management, entertainment and much more, and is designed to put users in control of their digital lives.
Currently, the Apple MacBook Pro whitepaper claims:
Processor and Memory working at the speed of thought
Oh, good, so now I can finally stop thinking on my own since apple found a way to cut years of advance research in quantum computing and artificial intelligence.
Microsoft and Apple are not alone. Here’s a quote from a Sun Jini:
These three facts (you are the new sys admin, computers are nowhere, the one computer is everywhere) should combine to improve the world of using computers as computers — by making the boundaries of computers disappear, by making the computer be everywhere, and by making the details of working with the computer as simple as putting a DVD into your home theater system.
And don’t even remind me of the fertilizer George Gilder spread about Java:
A fundamental break in the history of technology…
That’s one sure tip-off to the fact that you’re being assaulted by an Architecture Astronaut: the incredible amount of bombast; the heroic, utopian grandiloquence; the boastfulness; the complete lack of reality. And people buy it! The business press goes wild!
Why the hell are people so impressed by boring architectures that often amount to nothing more than a new format on the wire for RPC, or a new virtual machine? These things might be good architectures, they will certainly benefit the developers that use them, but they are not, I repeat, not, a good substitute for the messiah riding his white ass into Jerusalem, or world peace. No, Apple, MacBooks are not suddenly going to start reading our minds and doing what we want automatically just because they got a new processor. No, Sun, we’re not going to be able to analyze our corporate sales data “as simply as putting a DVD into your home theater system.”
Remember that the architecture people are solving problems that they think they can solve, not problems which are useful to solve. gRPC may be the Hot New Thing, but it doesn’t really let you do anything you couldn’t do before using other technologies — if you had a reason to. All that Distributed Services Nirvana the architecture astronauts are blathering about was promised to us in the past, if we used DCOM, or JavaBeans, or OSF DCE, or CORBA.
It’s nice that we can use GraphQL now for the format on the wire. Whoopee. But that’s about as interesting to me as learning that my supermarket uses trucks to get things from the warehouse. Yawn. Mangos, that’s interesting. Tell me something new that I can do that I couldn’t do before, O Astronauts, or stay up there in space and don’t waste any more of my time.
All I did was to replace the mentioned technologies in this 19 year old text with recent examples, as my friend and former colleague Herman Vöcke suggested on Twitter.
The result is an up-to-date blog post. And what does that actually mean?
It means that while we developers like to concentrate on solving technical problems we still have to – also after 19 years – solve problems in the real world. And it is a good example of how everything old is new again in our industry.
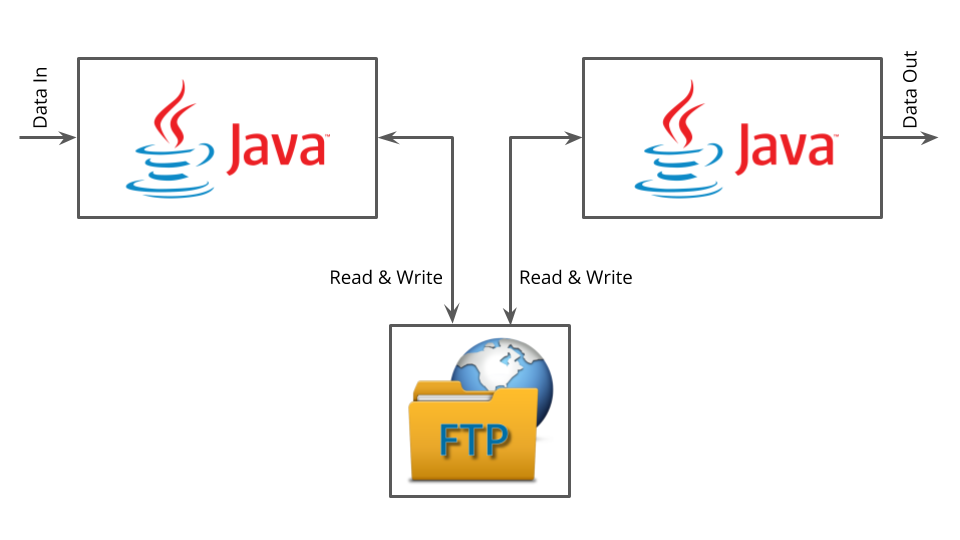
Since the 90s we know that Service Integrations via a shared file storage should be avoided. The system cannot be tested very well, debugging is hard and data not trustworthy as it’s manipulated by many sources.
Surprisingly, what we QAs of ThoughtWorks have observed in different teams with different clients over the past few months is a very strong tendency to service integrations via S3 buckets in Amazon Web Services (AWS). Many people (e.g. while Inceptions at the beginning of a project) that were working for our clients for many years actually suggested to read from / write to existing buckets. The main reason for those buckets to be widely used and accepted throughout the organizations were the data science projects that were starting or even already established in the companies.
Hence, the justifications we heard for such an integration between services was along the lines of “the data is there anyways” and/or “the data scientist will also need this data”. But being a data-centric or even a data-driven company should not compromise the way the integrations are built on the technical side. Doing “Data Science” does not require anti-patterns in architecture.
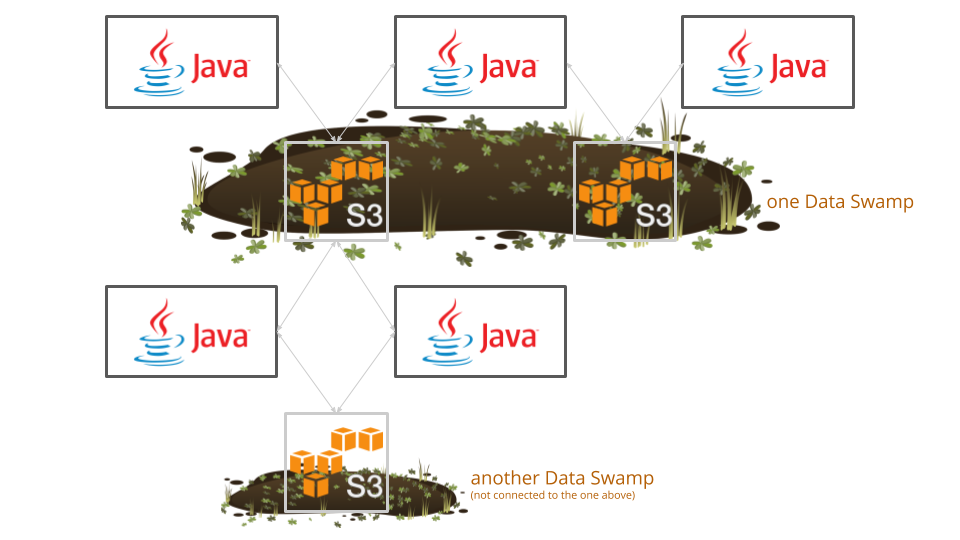
Also, we believe that this setup makes it actually more difficult to do accurate data science. No one could point us to a resource that helped to get an overview of what data is stored where. It’s unclear which data is used for what. Even worse, it’s not always possible to connect any two data stores in the data analysis. If we think of more than a couple of services, the integrations via S3 buckets looks like in the following diagram:
All of those services integrate via some S3 buckets. Those buckets are distributed throughout the architecture. Most of them already have old data but no one is really sure if it’s old data or still used as they have multiple read & write accesses and there is no way to keep an overview. This results in the current big data swamps we are working with. Mind the plural: swamps. Also, we don’t see them as clean lakes. Those buckets are sometimes not connected at all and the data is a pile of mud. This is what we reference to as a “data swamp”:
As QAs, we like to have clean integrations that can easily be tested and a clean flow of data through the system that enables debugging. It does not necessarily need to be predictive for big data, but an understanding of what type of data is flowing from Service A to Service B would undoubtedly be helpful. It is very hard to write integration- or maintainable end-to-end tests for those kinds of architectures with integrations of that kind. That is obviously one of the main motivations for us QAs to look more into this issue.
We advocate for a clean data storage for the data engineers and in our role we are actually in a good spot to do this: QAs typically care more than other people about Cross Functional Requirements (CFR). Storing masses of data in a proper system is as much a valid CFR as looking out for security, performance or e.g. usability.
Hence, in the last weeks we started discussing and we are wondering where this (quite enthusiastic!) buy-in for old anti-patterns is coming from. We are trying to understand more of the root causes of this type of architecture (besides doing “data science”). Does it come down to the typical “it’s quick to develop”, “we all understand the technology” or “we did not know what else to use”?
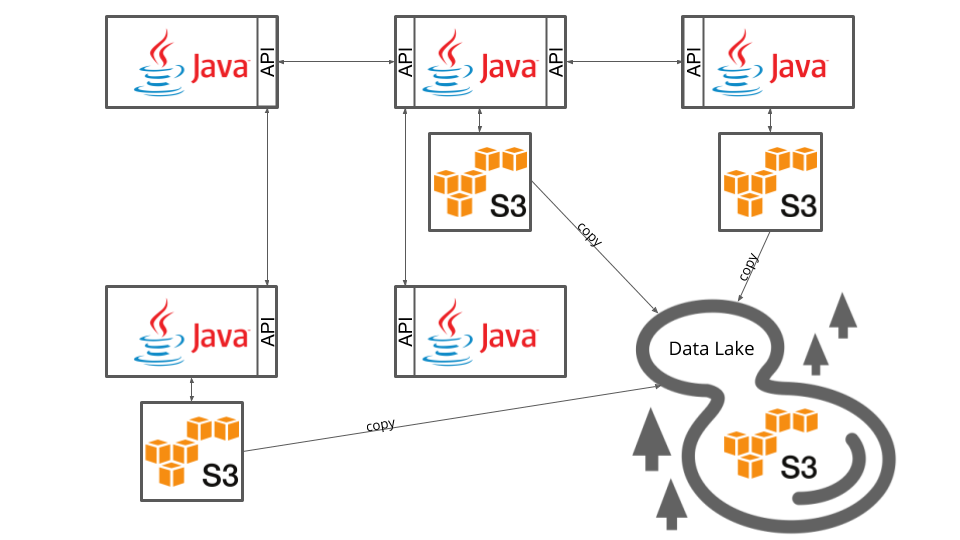
A more sustainable approach would obviously be to enable services to directly communicate with each other and not via shared file storage. That would allow any client to have stateless services that each store just the information they need.
That would allow us to build a more scalable system. It would allow us to test the integration between services much better – or at all for that matter! It does not necessarily all be via well defined APIs in synchronous calls. When one providing service has many consumers which only need new information at some point of time or if you have synchronous calls are cascading all through your system you may want to use something like the AWS simple notification service (SNS) instead (or Kafka to not just talk amazon here or rabbitmq or…). But any separation that is more structured will enable a company to actually scale faster.
But implementing APIs alone won’t do the trick. This suggestion for improvement has the base assumption of well split domains. I explained this in detail in this blog post.
Once you build a more structured architecture and have clean integrations, not only the future development of this application will benefit, there will also be a huge improvement for the the data scientists. When each service stores the relevant data on its own one can “simply copy”¹ the data and “do” any science on it. In one single place.² That would allow the data people to work on their own without the need of product teams building reports and data pipelines.
Footnotes:
“simply copying” the data may also involve some queues/messages. It should not be a local bash script that is literally copying. For static data analysis you won’t need real-time data anyways, in this case it’s fine if you need some minutes to aggregate, process and store the data.
“in one single place” may actually be different data stores: one for public information (like flight dates), one for not public information (like usernames/user identifiers) and yet another one for information that even most people of a company should not have (like financial data or user passwords).
Traditionally, when talking about the quality of our software, of our product, we discuss how we can ensure a certain level of quality. In this context quality is seen as a minimum requirement. The business value of quality from this perspective is in the prevention of potential losses, e.g. by downtime of a platform.
Today, we can see that this picture shifts dramatically. More and more companies move to a devops culture and we can see the same “shift left” happening in the QA space. Likewise, today’s businesses need to react fast to changes in the market. New technologies emerge faster than companies can pick them up.
We want to talk about a high quality product in this context. The high standard in our products does not just ensure our business and mitigate potential risk. High quality in our software allows us to build better software faster. It makes today’s product more resilient to changes in the future. We change our perspective and do not think how to ensure a certain (minimum) level of quality. But how high quality enables our business.
This talk is a shared effort with my colleague Nina.
Did you know you can enable your team to build better software faster while having a stronger team culture? Too good to be true?
In recent years, agile has influenced early involvement of testing in the development cycle. With this more and more testers are testing new functionality as soon as a commit is pushed. Yet such teams still fail to deliver high quality software. Why? What is missing?
Working with various diverse teams across multiple projects, Finn realised that testing doesn’t actually improve software quality. It’s just a bar assuring a certain level of quality that already exists. In order to actually improve we must get involved into much more than simply testing and think about the product as a whole.
In this session, Finn will share specific examples of how engaging with the business, engineering, process optimisation as well as the entire cross-functional team can lead to significant improvements in the product’s quality. At the end of the talk, you will know how to start with a holistic approach to improving product quality throughout the entire software delivery lifecycle.
— this is a talk I am currently doing on various conferences. Some people asked me if I can share the slides, but the files are just a bit too large. So instead I decided to include a recording of the talk (with the slides) here, as some of them only play well with the presentation.