This post is all about deploying every single commit to the production environment.
All manual steps in a release cycle can be automated – even if you want to check your designs. This post explains step-by-step how to automate each single one and what to consider when releasing a couple of times per day. You can find my article in the Otto dev blog. Or you can read it below.
Whenever we present how we release features and deploy our code in one of OTTOs core functional teams, we are met with a certain set of questions, e.g..: “Why do you want to deploy more than once a week?”, “If you automate release and test management, what are the release and test managers doing?”, “How can we prevent major bugs to enter the shop?”, “Where is the final control instance to decide if something goes live?”, or the typical question “Who is responsible if something breaks?” or simply “Why the heck would someone want to do this?”
Let us answer those questions. Let us guide you through our way of working. Let us show you what processes we have (and which ones we do not have) and give you a hint on how to increase productivity and quality at the same time (without firing the test manager). All you have to do is to sit back, relax and let go of your concerns to lose control. Don’t worry, you won’t lose it.
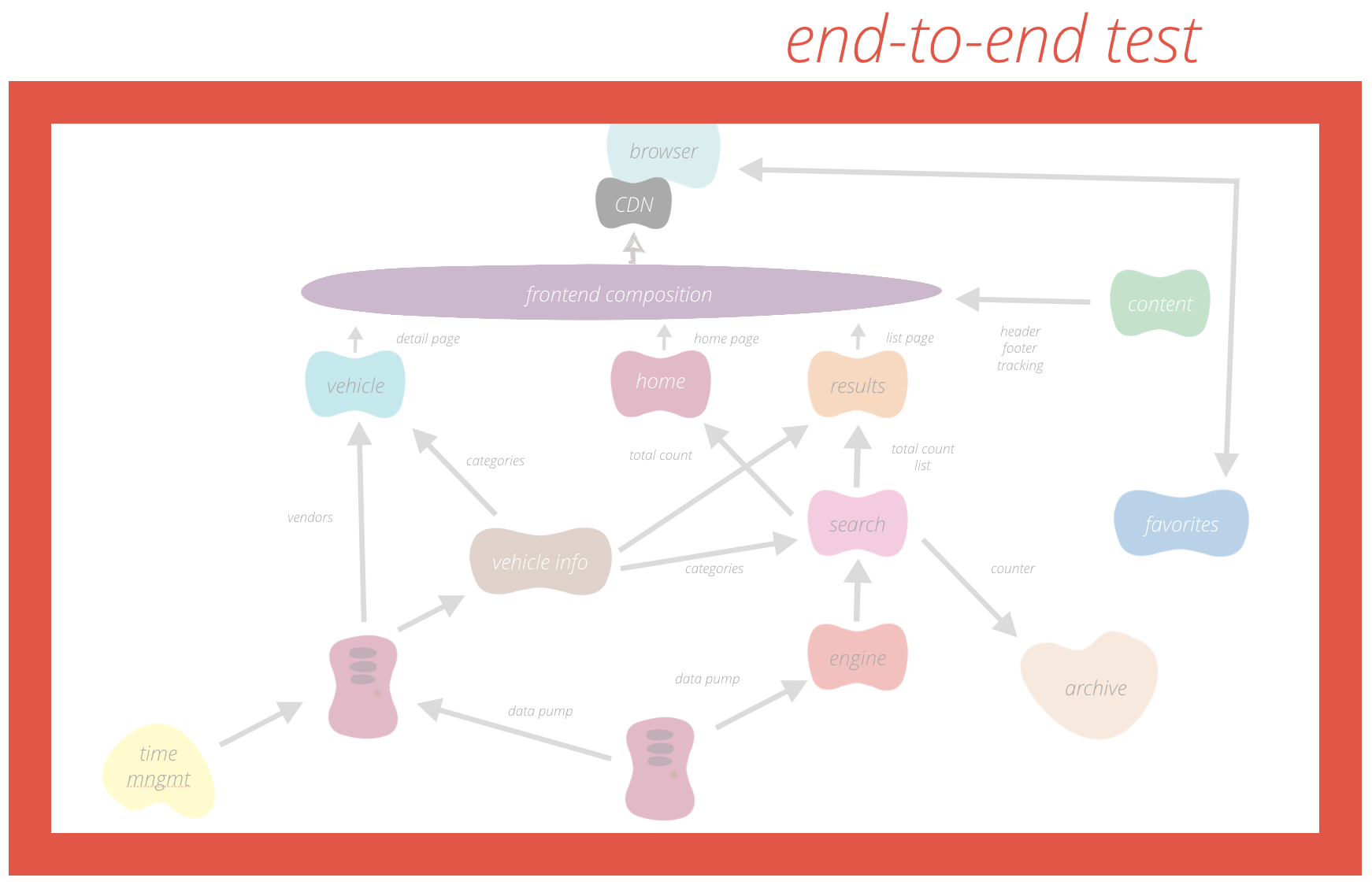
If you have a look at a general release process for a deployment, it will look similar to this scheme:
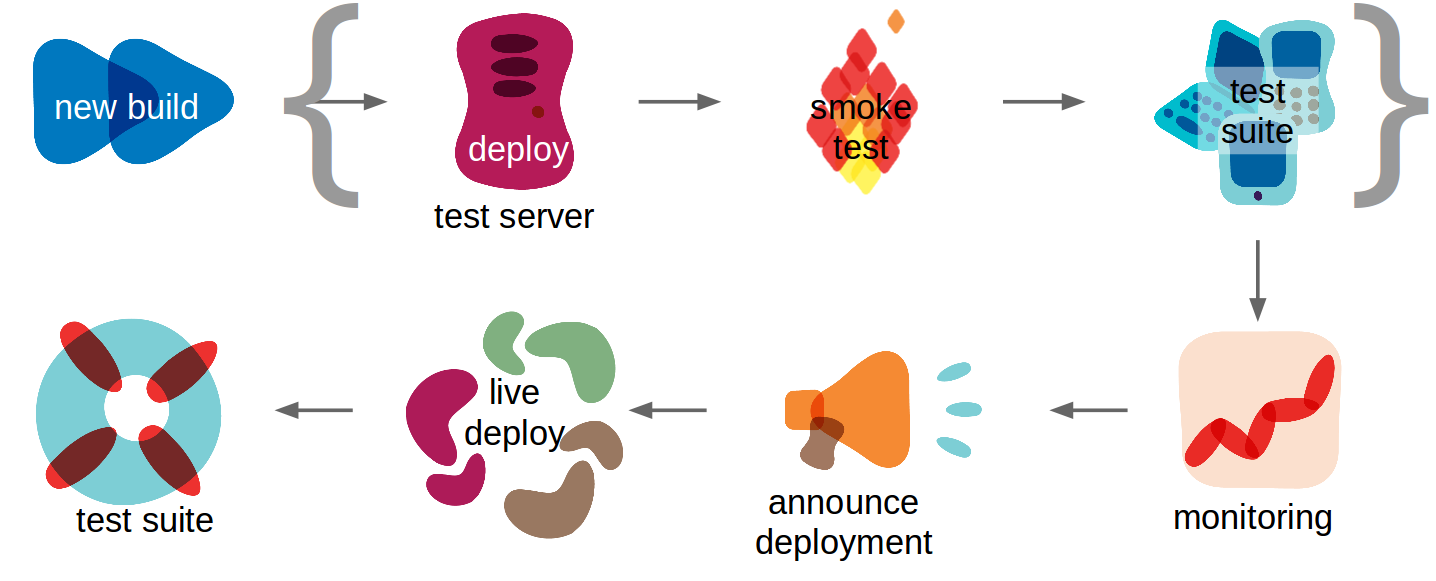
The image illustrates a release life cycle: Occasionally, a new release candidate is built. If the code compiles and first tests are successful, we speak of it as a “green build”. The code of this release candidate is deployed to a test server and after a smoke test a full test suite can run. Depending on the number of test servers and your (integration) test setup, you may want to repeat steps 2-4 for more than one server. If all tests pass for a specific build version, and the live platform is stable (→monitoring step) you can announce the live deployment and ship the new build. Probably, some tests will ensure that the live deployment was successful.
Not a single one of those steps requires human interaction. The entire process can be automated. One of the many advantages is that you simply do not have to spend time on this process. The time that is now free (most of the times this will apply for the Quality Analyst) can be spent on other tasks. In our case, we could almost double the time the QA spends with the developer and business designer.
Before that, the Quality Analysts were only able to evaluate the quality in a given piece of code after the implementation. If this code did not meet the expectations for “quality”, they would need to convince stakeholders and developers that the quality was not sufficient and the developers would start the story once again. This was a very time intensive and thus expensive process.
Now, the Quality Analysts have more time to review the business requirements, think about edge cases and report them to the developer before implementation. Furthermore, the QAs are pairing with the developers and can make sure, that “quality” is engraved in the product during implementation.
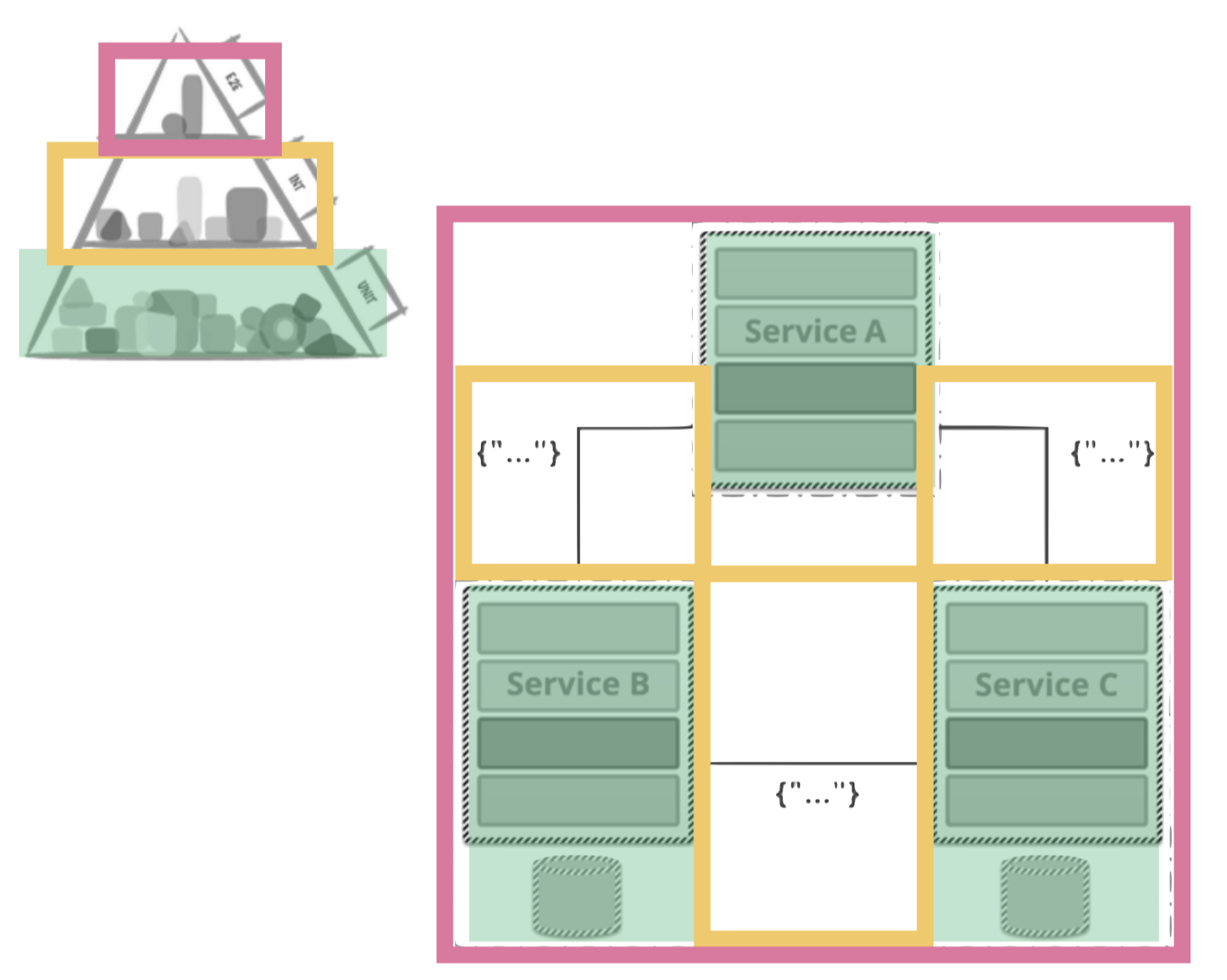
 The build that triggers the entire process, has a lot of tests itself already. We keep tight track of our test pyramid in this first step of our test automation. At this point we have a huge amount of unit and a fair portion of acceptance tests. They not only test our Java code base. We apply the same principles to our JavaScript: to reduce the number of frontend (Selenium) tests possibly needed at the end of our build pipeline, we prefer fast feedback of a lot of JavaScript tests in the initial build step, using Jasmine.
The build that triggers the entire process, has a lot of tests itself already. We keep tight track of our test pyramid in this first step of our test automation. At this point we have a huge amount of unit and a fair portion of acceptance tests. They not only test our Java code base. We apply the same principles to our JavaScript: to reduce the number of frontend (Selenium) tests possibly needed at the end of our build pipeline, we prefer fast feedback of a lot of JavaScript tests in the initial build step, using Jasmine.
If all those tests pass, we consider a build “green”. Our build runs for every single git commit.
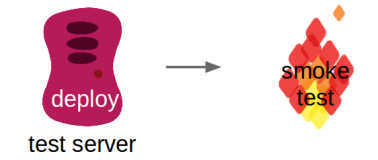 The next step is to deploy a green build to a test server and continue testing the new software. Talking about deployments, one often forgets that it is code executing all the steps necessary to provision a server with new software. Even this code can fail and thus, we recommend a small smoke test to be executed right after the deployment. This can be as easy as checking the version number on a status page or the git-hash in the meta information on the front page. You will save a lot of time to not execute tests on old code.
The next step is to deploy a green build to a test server and continue testing the new software. Talking about deployments, one often forgets that it is code executing all the steps necessary to provision a server with new software. Even this code can fail and thus, we recommend a small smoke test to be executed right after the deployment. This can be as easy as checking the version number on a status page or the git-hash in the meta information on the front page. You will save a lot of time to not execute tests on old code.
 Having the software successfully deployed to the test server, we then continue testing. After covering the base of the test pyramid in the build step, we now take care of the top of it. Here we will execute more acceptance and functional tests, some of them in Selenium. Furthermore, we can run first integration tests with other teams, other services and maybe third party software. For integration testing, we do not rely on Selenium alone. We have a wide set of so called CDC tests (consumer driven contract tests) with other teams. If other teams have specific requirements e.g. for our APIs (= they consume our API) they would write a test that runs within our build pipeline, e.g. a pact-test. In this way we can make sure that all requirements other teams have towards us are fulfilled for every single commit.
Having the software successfully deployed to the test server, we then continue testing. After covering the base of the test pyramid in the build step, we now take care of the top of it. Here we will execute more acceptance and functional tests, some of them in Selenium. Furthermore, we can run first integration tests with other teams, other services and maybe third party software. For integration testing, we do not rely on Selenium alone. We have a wide set of so called CDC tests (consumer driven contract tests) with other teams. If other teams have specific requirements e.g. for our APIs (= they consume our API) they would write a test that runs within our build pipeline, e.g. a pact-test. In this way we can make sure that all requirements other teams have towards us are fulfilled for every single commit.
Maybe you do not have just one test server, but two (e.g. for different kinds or levels of tests). Then you would execute the deployment-and-test steps two or more times. In any case, the number of tests should decrease with every step, otherwise there is something fundamentally wrong with your test pyramid.
One big concern I am met with is that no one looks at the product before it goes live. “Automation is nice, yes, but nothing beats the pattern sensing of a human brain” is what people mention in response to all the automation. The statement is true, no doubt. But the point is, that the value of a human brain is not necessarily needed here and can be better applied earlier in the process of the software development.
 To explain this, let me tell you about one fundamental requirement to release automatically: that is the consequent use of feature toggles. Using toggles means that new features are not released by a deploy but by a flip of a button. This has two major advantages: First, the feature will have a shorter time to market. Just a few minutes after the last commit is pushed the entire feature code is deployed. One does not have to wait until the end of e.g. a sprint cycle. Second, despite all human and automated tests sometimes something just goes wrong. (And it does not even have to be a technical problem). Thus, if we release a feature with a toggle, we can also toggle it off in just one second. We do not have to rollback our deploys and hence we do not affect other features that were in the same deployment. The process automation made our deploys an absolute “non-event”, while the side effects of the quick deployments made feature releases a lot easier.
To explain this, let me tell you about one fundamental requirement to release automatically: that is the consequent use of feature toggles. Using toggles means that new features are not released by a deploy but by a flip of a button. This has two major advantages: First, the feature will have a shorter time to market. Just a few minutes after the last commit is pushed the entire feature code is deployed. One does not have to wait until the end of e.g. a sprint cycle. Second, despite all human and automated tests sometimes something just goes wrong. (And it does not even have to be a technical problem). Thus, if we release a feature with a toggle, we can also toggle it off in just one second. We do not have to rollback our deploys and hence we do not affect other features that were in the same deployment. The process automation made our deploys an absolute “non-event”, while the side effects of the quick deployments made feature releases a lot easier.
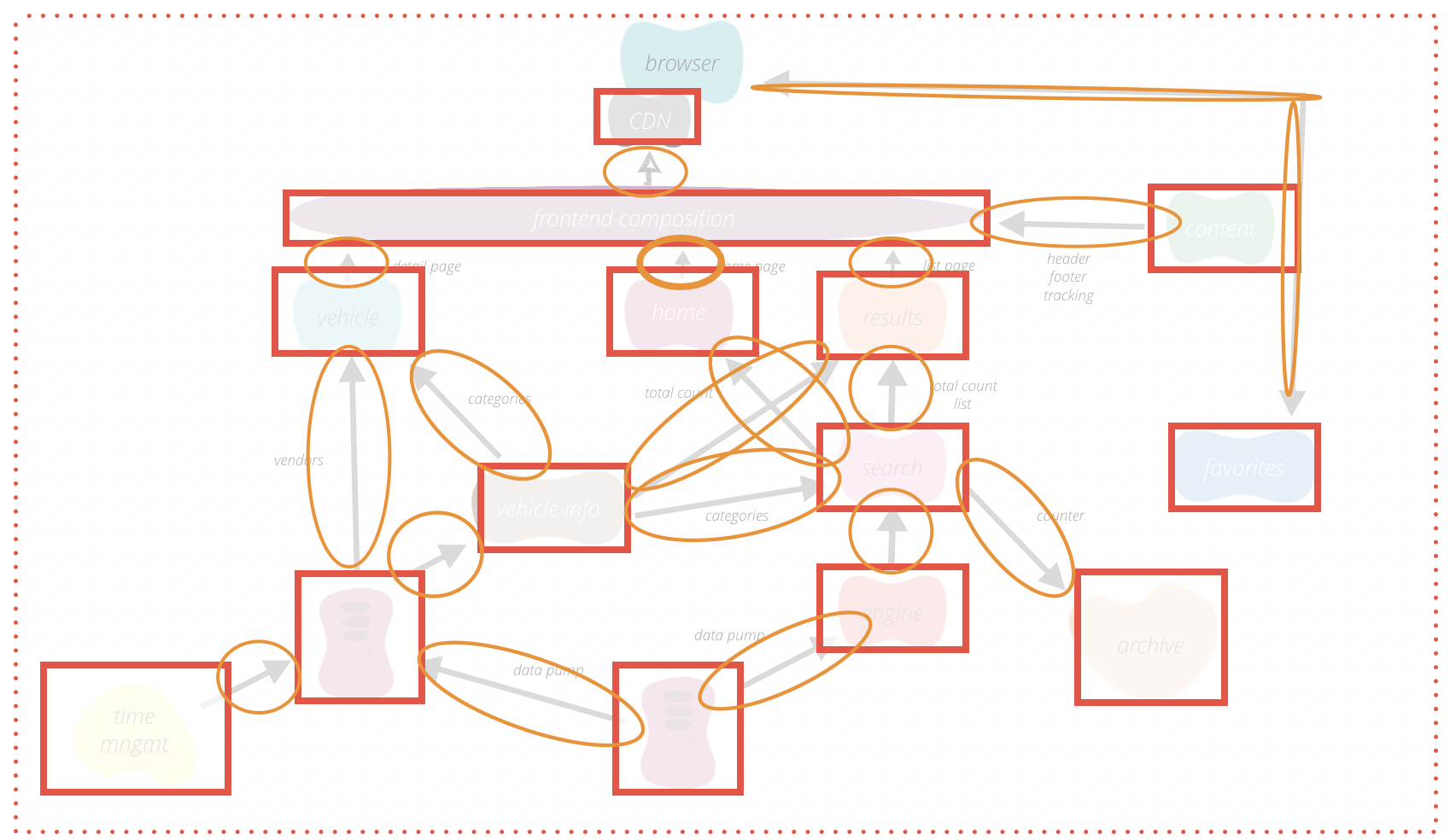
With the fact that (almost) all, especially the frontend changes, are toggled, no deployment should ever change the face of our product. And this is difficult to test for humans. Human brains are activated by mismatching patterns. Different paddings for otherwise equal elements or a picture that is out of its box are very easy to spot for us. But if one link in a list of maybe 20 links is missing on a page, almost no one will notice. If the link would turn green, or would have a different font than all other text, we would discover it right away. If it’s simply gone, we barely notice it. Hence, for our kind of deployment we need either a human with an identic and photographic memory – or a machine. We decided to go with the latter. Inspired by other tools, such as “wraith” by BBC we built a small ruby gem (lineup) that uses selenium to take screenshots of defined pages of our product before and after the deploy. It will realize as soon as just one pixel changes and fail the test step. This lets us detect, whether or not our feature toggles were implemented correctly and discover undesired front end changes before they go live. Here is an example:
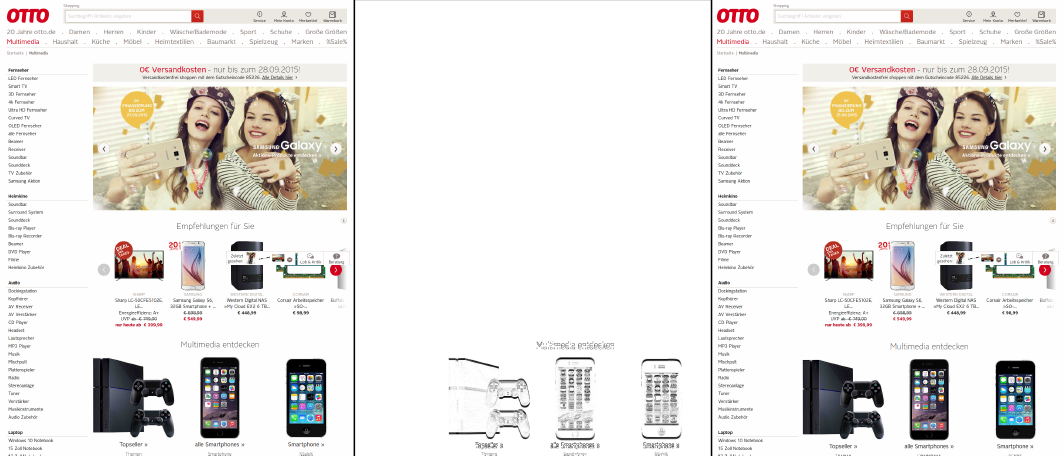
On the left side is an entry page before the deployment of the new code and on the right side after the deployment. Unless starting complicated measurements, no human would notice the increase in the top-margin of the headline of the smartphones and the gaming console. The image comparison (middle) between the base (left) and new (right) image reveals the difference right away by marking all pixels that have changed between the left and the right image.
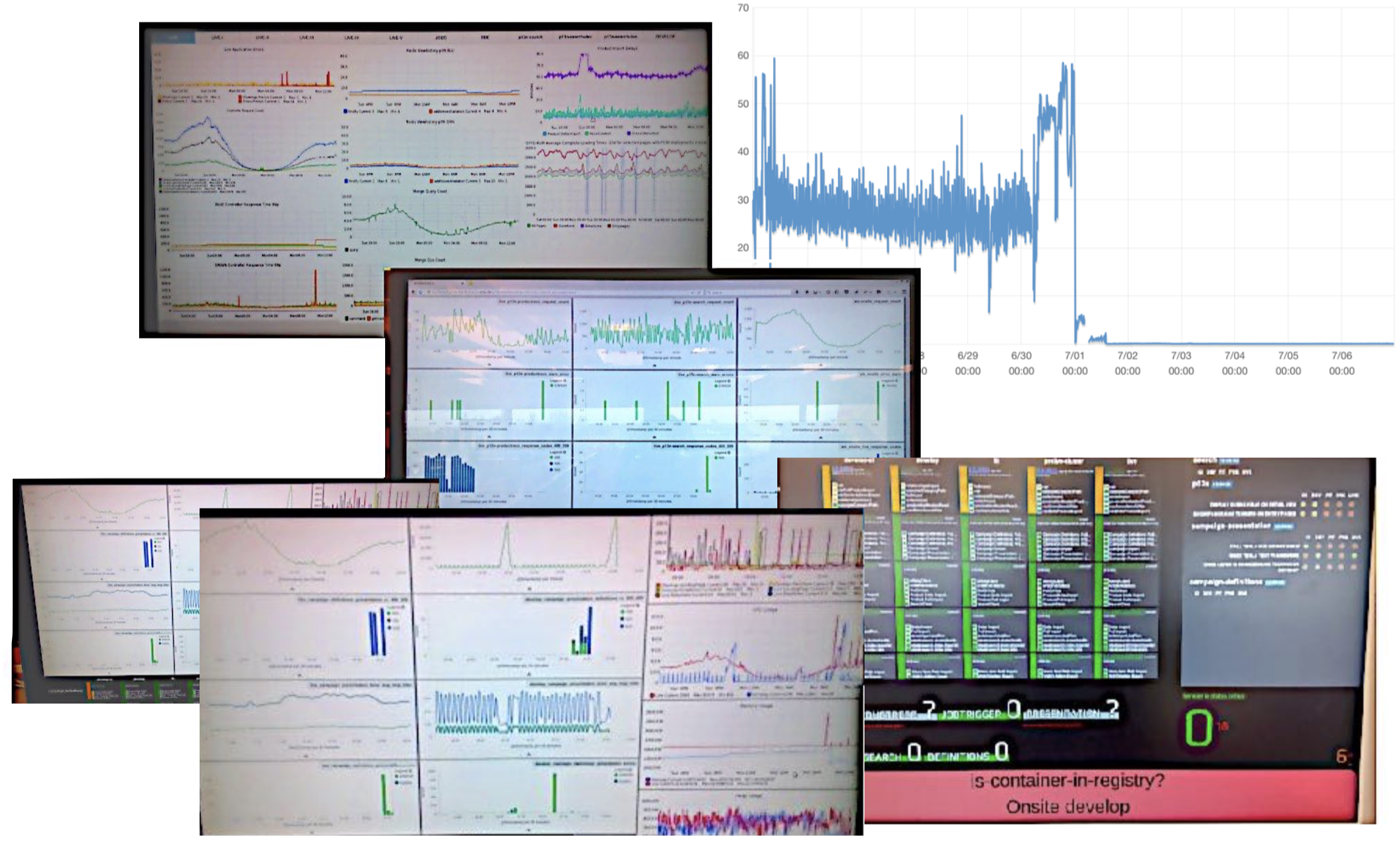
 If the build passes this last test, it is good to be deployed to the live platform. To ensure, that our platform is always stable enough for a deployment we constantly monitor the servers and databases. This is (and needs to be) a shared team responsibility – just as any other step of the entire process. We achieved this by simply putting up a couple of monitors that are in the line of sight of every team member. Every day, we discuss the error rates and possible performance problems in front of the big screens. This general discussion and the come-togethers around the common screens enhanced our culture of constant monitoring. With more and more services being built we are now investigating ways to focus on the most important metrics. As the issues on our live servers are different every day, we cannot determine which metric “is key” for what service. Hence, we have to automatically analyse all our metrics and present only the most relevant ones to the team. The most relevant ones are usually the weirdest. Thus, our investigations currently go into the direction of anomaly detection.
If the build passes this last test, it is good to be deployed to the live platform. To ensure, that our platform is always stable enough for a deployment we constantly monitor the servers and databases. This is (and needs to be) a shared team responsibility – just as any other step of the entire process. We achieved this by simply putting up a couple of monitors that are in the line of sight of every team member. Every day, we discuss the error rates and possible performance problems in front of the big screens. This general discussion and the come-togethers around the common screens enhanced our culture of constant monitoring. With more and more services being built we are now investigating ways to focus on the most important metrics. As the issues on our live servers are different every day, we cannot determine which metric “is key” for what service. Hence, we have to automatically analyse all our metrics and present only the most relevant ones to the team. The most relevant ones are usually the weirdest. Thus, our investigations currently go into the direction of anomaly detection.
The growing number of services (as a result of the change towards Microservices) helps us  to keep the impact on any other system but the deployed one as small as possible. Having only loosely coupled services, removes the need to announce every deployment to all other (~dozen) teams. If other teams were affected by our changes and/or deployments we would have a fundamental flaw in our architecture (or in our CDC tests). To develop and enforce hard- or software locks at the end of the release process in order to limit the deployments is not a solution for this rudimentary architecture challenge. Hence, there is no need to announce deployments to the entire IT department. It is probably a good thing though to let the ops people know about our deployments in general. And one should also have a single gate that can be closed for all deployments if something is preventing deployments in general at a particular moment. Finally, the last thing we need is a deployment reporting for documentation purposes. This usually only includes what git hash/build version went live at what time including a changelog.
to keep the impact on any other system but the deployed one as small as possible. Having only loosely coupled services, removes the need to announce every deployment to all other (~dozen) teams. If other teams were affected by our changes and/or deployments we would have a fundamental flaw in our architecture (or in our CDC tests). To develop and enforce hard- or software locks at the end of the release process in order to limit the deployments is not a solution for this rudimentary architecture challenge. Hence, there is no need to announce deployments to the entire IT department. It is probably a good thing though to let the ops people know about our deployments in general. And one should also have a single gate that can be closed for all deployments if something is preventing deployments in general at a particular moment. Finally, the last thing we need is a deployment reporting for documentation purposes. This usually only includes what git hash/build version went live at what time including a changelog.
 As described above: the deployment to the live servers became an absolute non-event and thus there is nothing noteworthy for this blog entry for this step. After the deployment is finished, we run a small test suite to make sure that our code was successfully released and our core functionality is still in place.
As described above: the deployment to the live servers became an absolute non-event and thus there is nothing noteworthy for this blog entry for this step. After the deployment is finished, we run a small test suite to make sure that our code was successfully released and our core functionality is still in place.
And then we are already live, multiple times a day. And while we increase our shipping speed, we have even more time to ensure that our product is built in a good quality. To execute all the steps, we have created a wide range of tools. For most steps, the available open source tools did not fit with one primary need: The entire process is automated, thus coded. This code, as any other, needs to be tested. Hence, we think of our release pipeline as testable code. This is reflected in the build tool „LambdaCD„. Additionally, we built the described image comparison tool „Lineup„. Another team at OTTO developed a monitoring solution („Oscillator„) and even for tracking deployments, feature toggling and other events, we built our own set of tools. To be open sourced soon.
For further reading check out:
Have a look at the features of our open source projects. And – please! – give us feedback about your opinion and experiences.
Your FT3 Team