One year ago I introduced the “muffin concept” in a small blog post, “how we do Quality at ThoughtWorks”. Ever since then I have been to various Meetups and Conferences to discuss the idea and all the concepts behind it. After another year and dozens of discussion, there are more thoughts around how to bake quality in. It covers quite different aspects, thus I decided to split this post into a miniseries of 5 posts.
Enjoy the read and please give me feedback: tell me what you think!
People say that quality is like the chocolate on a muffin. Is it? Let’s say the product we build was indeed a muffin. The business analyst brought the recipes, and the developers baked it. Afterwards, the testers put chocolate on top.
If I imagine the muffin, it’s still a bit dull. The muffin is only perceived to be of really high quality if there are some chocolate chunks on top: like testing software.
The only problem is that – just like testing in the software delivery process – the chocolate is only “applied” after baking the major part of the product. It looks good and smells good. But does a muffin with a very few chocolate chunks only on top really taste better?
No, because there is no chocolate inside the muffin, just like testing does not improve the quality of a software:
When you test software you basically analyse a (hopefully) isolated system in a controlled environment. And no matter what you do, that system does not change. You may find behaviours in the system that are unexpected (which are the bugs / defects we are trying to find). But they were in the system already (before you started your test case) and they will be in there afterwards. No system under test does ever change its state (exception: quantum mechanics). Thus, the system does not evolve or improve (in quality) while you test it. Yet, another cycle of development in necessary to actually improve quality.
But that is quite sad. I am a quality analyst. An enthusiast. Caring about the quality of my product is my job description. Usually I am the team member most passionate about it. How can I be the only one who is not able to actually improve the quality?
With this mini-series of blog posts we want to investigate how we can be involved to improve quality in software early on – how to bake chocolate into the muffin!
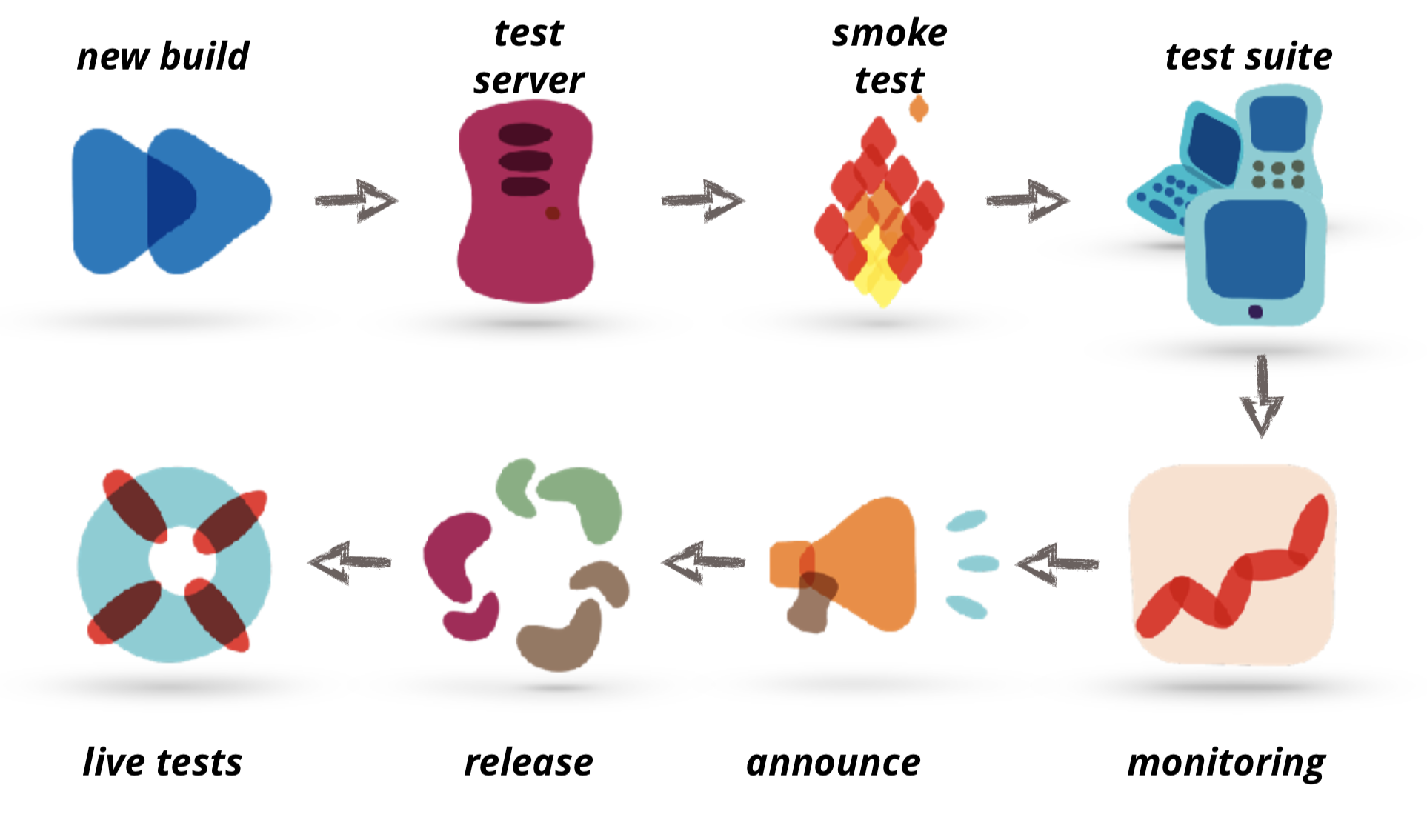
Usually, a typical day in the life of a tester may look like this, where you pick a new build, deploy it to a test server, run smoke test and your extensive test suite. Possibly its (partly) automated. When no blockers are found one would monitor the production environment, ensure everything is healthy and announce & ship the build to production. Maybe you have a test suite running in production to ensure your delivery there:
However, that is only the last bit of a longer process. Normal, agile software delivery teams have a process that looks similar to the following one:
Each column is often reflected in tools like Mingle, Trello or Jira: “in analysis” is the step where Product Managers or Business Analysts work out the requirements for the projects. Once they are done they move into the next column. That could be a planning meeting where a sprint backlog is filled. We call the backlog “Ready for Dev” column. At some point devs pick up a story, works on it, finish it and put it into “Ready for QA” until a QA picks it up, works on it and ships it. Then a story is finally done.
If a defect is found in the QA work in the best case the ticket needs to go back to the devs or all the way back to in analysis. With these long feedback loops it can take a while until all kinks are out of a new piece of functionality.
Here we want to tighten the feedback loop and get involved earlier. Here is exactly the point where we can improve quality early on and where we can measure it. We identified four different fields where we are usually involved and where we have an actual impact on the quality of our product. You can read about each one of them in an individual (small) post:
Those four points is our recipe to bake quality in: You add some chocolate early on by process improvements. Then we add some technical strawberries along with the right amount of cream in the business space. We finish it off with some colourful sugar toppings in the team culture and voila… we really bake quality in!
With this holistic approach, we also step beyond being pure “Quality Analysts”. We still analyze the quality of software. But we also specialize on so many more things that lead to a better product. Thus, we truly are Product Quality Specialists.
On Tuesday, March 28th I was invited to Hamburg. ThoughtWorks has a long running series of Meetups in our Hamburg office. I had the honor to be the next person to present there.
For this occasion we talked about how to build a high quality product and what the differences and implications are to talking “only” about a high quality software. We discussed what ways we can think of to improve quality and measure quality and what we should be looking at other than business requirements and bugs in a software.
It was a very nice evening with lots of participants. We had many interesting questions that led to even more interesting discussions. I am looking forward to the next time already. Not only to see old colleges in Hamburg but to continue with all the talks and thoughts.
Episode 21: How ThoughtWorks helped Otto.de transform into a real DevOps Culture
Finn Lorbeer (@finnlorbeer) is a quality enthusiast working for Thoughtworks Germany. I met Finn earlier this year at the German Testing Days where he presented the transformation story at Otto.de. He helped transform one of their 14 “line of business” teams by changing the way QA was seen by the organization. Instead of a WALL between Dev and Ops the teams started to work as a real DevOps team. Further architectural and organizational changes ultimately allowed them to increase deployment speed from 2-3 per week to up to 200 per week for the best performing teams.
In Part II with Finn Lorbeer (@finnlorbeer) from Thoughtworks we discuss some of the new approaches when implementing new software features. How can we build the right thing the right way for our end users?
Feature development should start with UX wireframes to get feedback from end users before writing a single line of code. Feature teams then need to define and implement feedback loops to understand how features operate and are used in production. We also discuss the power of A/B testing and canary releases as it allows teams to “experiment” on new ideas and thanks to close feedback loops will quickly learn on how end users are accepting it.
The Quest for Quality is a conference in Ljubljana for first time ever. It was very well organized by Nikola and Evelina from Comtrade. I was very happy to talk for the closing note on the first day.
Find the slides of the talk here (PDF, opens in new tab): level-up
In my last post I wrote about how to test micro services. When I wrote about the most difficult part of the testing, the integration, I said that it would blow the size of a post to go into the necessary details. I am sorry and I want to make up for it here.
When we design and create the interaction (and thus integration) of different services with each other we rely very much on the principles of “Consumer Driven Contracts“, in short CDCs. These Contracts can be tested. While the basic idea seems simple (“let other test the things of our service they think they need”) it implies a change in the way how we think of who-tests-what. So I want to spend some time explaining the concept step by step in many pictures:
Imagine you are part of a team (the blue team) and work with another team (the purple team). The purple team’s service will ask the service of the blue team about the email address of a specific user (ID). They agreed – for the sake of the argument – to communicate in json format via a RESTfull interface. In other words: the consumer (purple team) has a contract with the provider (blue team).
Now our friends in the purple team want to make sure, that the blue team will always give them an email as an answer. The first important thing is that the purple team needs to trust the blue team in figuring out the right email address for the given user. If the purple team starts to validate the blue team’s results for the actual content you have a lack of trust. This is a different, much more severe problem. Writing CDCs does not help you to solve this.
Hence, the purple team tests that they get any answer and that it contains an email address (at all). They will not test which one.
So assuming the blue team does it all right, the purple team would then just write a test that sends any ID and gets back any email in a valid json.
Now, whenever the purple team wants to know if the contract is still valid they let the test run. But then think about when the contract would potentially break: in this picture the contract will only be broken if the blue team introduces (unintended, not communicated) changes to their service. So isn’t it a much better idea to run this specific test whenever there is a change to the service of the blue team?
And this is what we do: the purple team – the consumer –drives the the contract to make sure it holds up to the agreed functionality of the blue team’s service. In this way – having the test of the purple team in the CI-System of the blue team – the blue team can make sure to not accidentally break the contract.
A few days later, when everything works smoothly and both teams feel comfortable, the blue team does not need the purple team any more to do a release. The blue team knows that the test they received from the purple team discovers all flaws. The purple team can concentrate on something else.
This is it! This is the basic idea of the CDC. The purple team writes and maintains the test. But the blue team executes it. If the request would go the other way around (the blue team sends an email and expects back an ID), then the test would be written by the blue team and executed by the purple team.
But this is only the start. Of course, the blue team has more than only one service. And there is not just the other purple team, but many teams doing requests to the different services of the blue team. Now the blue team members have to be quite disciplined and ask the other teams for all the CDCs. This sound a bit like an overhead and quite exhausting. But here comes the big benefit: the blue team is in all its work (and more important: deployments) independent of the other teams and independent of the availability of the other teams services in test environments.
Anyone who tried to get multiple services of various teams running in different (test) environments will smile now knowing of all the pain this usually inflicts. In this picture the blue team mitigated this risk/problem.
While the blue team is doing quite well there is more to it. Being independent of other teams and their services is nice. But still you have dependencies between your own single services. You should also resolve those. Cover the connections between the services of the team with CDC tests, too. It will give you:
fast feedback (surprise!)
independent deploys
reduced complexity
Each of those three points on its own leads to a quicker development of features and a reduce in cycle time. As I get the combined benefit in this situation there is nothing I would argue against, so lets do it!
If all tests are in place, each service of the blue team is totally independent. It can be deployed at any time and still make sure the other services work properly.
And did you realize what this means? We do not need a big, heavy, error prone and expensive set of selenium end-to-end tests. We mitigated so many risks already and can be sure of interactions that are working.
You cannot test anything here, but certainly a lot. In any case, improving a lower layer of the testing pyramid usually implies that you can reduce something at the top. That means: less end-2-end test => less time for maintenance => more time to grow out of the role as a classic test manager.
Over the last couple of months I have often been asked about micro services, especially how to test them. Building a small (e.g. a micro) service usually requires a different approach towards the architecture and towards the services themselves. In many cases also the team structures changes (like Conway’s Law, just the other way around). The question that arises then is how we can “compensate” for it while testing. Or to be more precise: how to adopt our way of working to ensure a high quality software.
There are three major themes that need to be taken care of when we think about testing micro services:
The many times referenced testing pyramid principle apply here as much as for a monolith. And not just for one single service. The principles are as important when it comes to testing different service’s interactions.
Automation plays a key role in order to speed up your build and deployment pipelines. Maybe this applies even more for micro services than for other architectures.
Its not easy to start with a good micro service landscape and there certainly is some overhead in setting things up (the first time). But the benefit of small and independent services is the fast feedback you can receive.
The second and third points are mentioned most of the time, when someone talks or writes about working with micro services. The testing pyramid is not really new and there is not too much detail about the testing of those little services. So we will look into this even more, as indeed, there are some pitfalls you should avoid in order to have a properly testable service landscape.
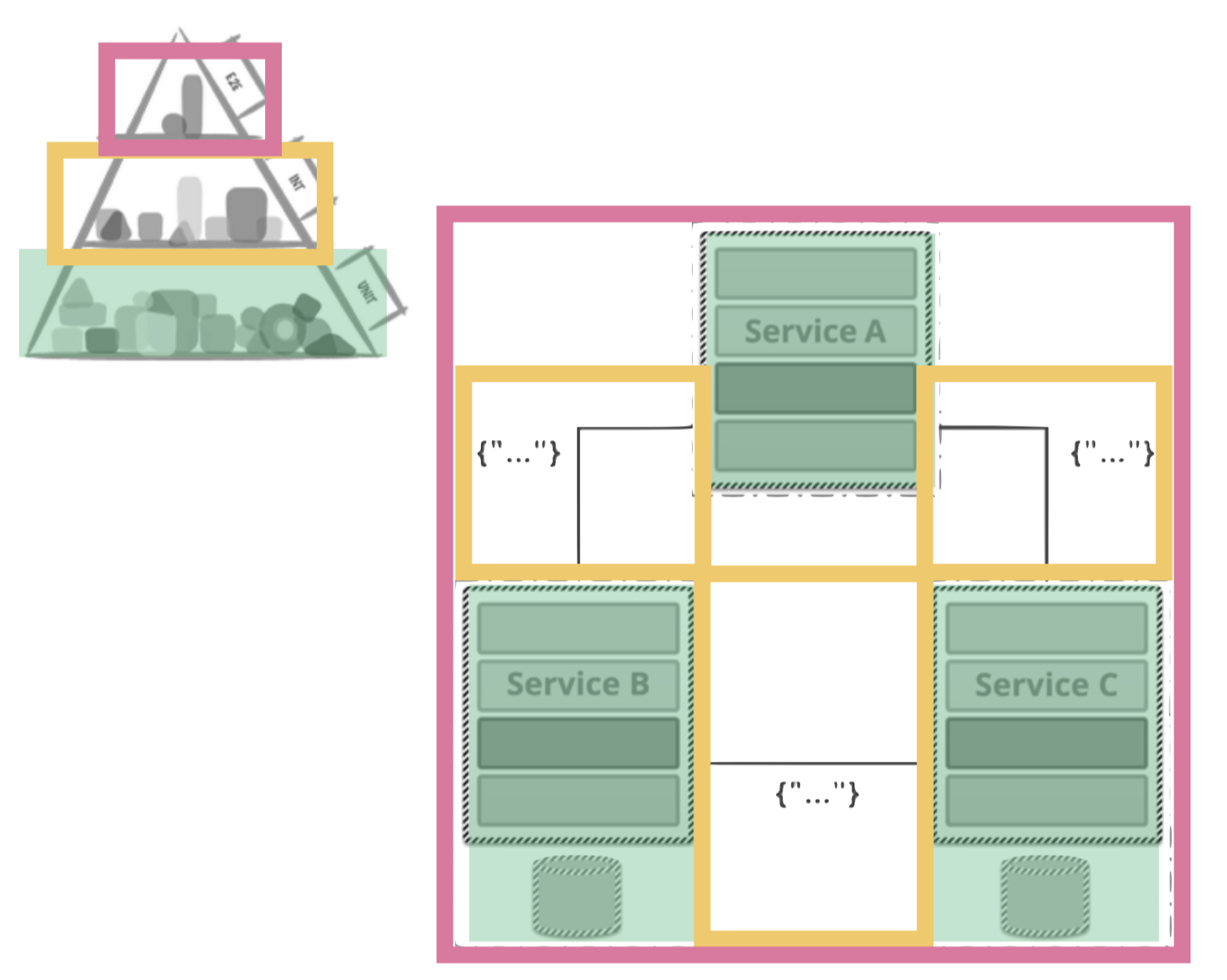
If we have a look at a monolith, things are straight forward: it is pretty clear where and how to apply the testing pyramid. The basic components of our services are unit-tested, their interaction is integration tested and then there is probably one end to end test around the entire service.
The testing pyramid for a micro service. The scheme of the service is by Toby Clemson from martinfowler.com
Now a “micro” service is (in this abstraction) nothing but a small monolith. In other words: treat the service itself as you always did. Be sure that the unit test coverage is really good. Find the places where you need to test the integration and then put as few as possible (in some cases: 0) end-to-end tests on top.
Up to here, there is nothing breaking new. But any project dealing with only 1 micro service has no big issues with testing. The real problems arise, once you have two, three or many services. The big difference to the monolith-world is that you have a lot more interaction via the HTTP clients. Lets have a look at an example.
Lets assume that the product we want to build is some kind of messaging system. There are three mayor features (see green boxes in the image):
The dashboard page where the user is going after login and sees a greeting. On this dashboard, also unread messages are displayed.
The inbox itself, all messages can be viewed here
The entire messaging system has some super strong encryption.
Although those features are very clear, we have a look at the business domains. The first domain we can identify is the user (“Finn”, the black circles). The user has a dashboard and an inbox. The second domain are the messages (yellow circles). They are displayed on the dashboard and in the inbox. The messages are also encrypted. The third domain is the encryption itself (blue circle). The encryption only works with messages.
Those circles represent the domains. If we cut our system according to the circles, we will end up with a clear domain for every service.
Service A deals with the user (and probably owns the html). Service B takes care of the messages. And Service C is doing the de-/encryption. For each single one of those services we apply – as described the testing pyramid. Then we put them together and view the entire system. And we consult our pyramid once more:
(side note: the level of tests we are discussing here is completely independent of the tools you may use. The integration tests can be PACT tests or CDCs, they could be written in Selenium or you could use Appium. But we do not want to talk about single tools here, rather about the general concept)
The single service itself is the unit. We know its properly tested and the unit is working as expected. There are a lot of tests in place to make sure this is the case. The base of the pyramid is ok.
The integration becomes very tricky. This is new and was/is not needed in the world of monolithic applications. There is one thing you really – really! – need to be aware of: test the interaction itself – and not two services. If you have to get two services up and running to make sure that one is working properly it does not sound too bad. But if you scale and you have to get 27 services up and running to test one it just will not work. Too much complexity for a test run. The challenge is that you will want (need) to test the integration of “your” services without the other ones. An approach that works really well are the consumer driven contract tests. It will blow the scope of this post to explain the concept here again – so I wrote a different post only about those CDCs. Make sure to dig into this!
If you got the trick with the integration, then the rest is “easy”. You will run the standard set of end-to-end tests. And once you have a good feeling about the integration and contract tests, then you will probably also reduce the amount of costly end-to-end tests. If you got all of this in place it would be perfect.
So much for the theory.
While this seems to be a simple principle, the real world looks very different. In many cases I have seen micro services being carved out of an already existing monolith. Furthermore, this usually happens under time constraints and has to be done fast.
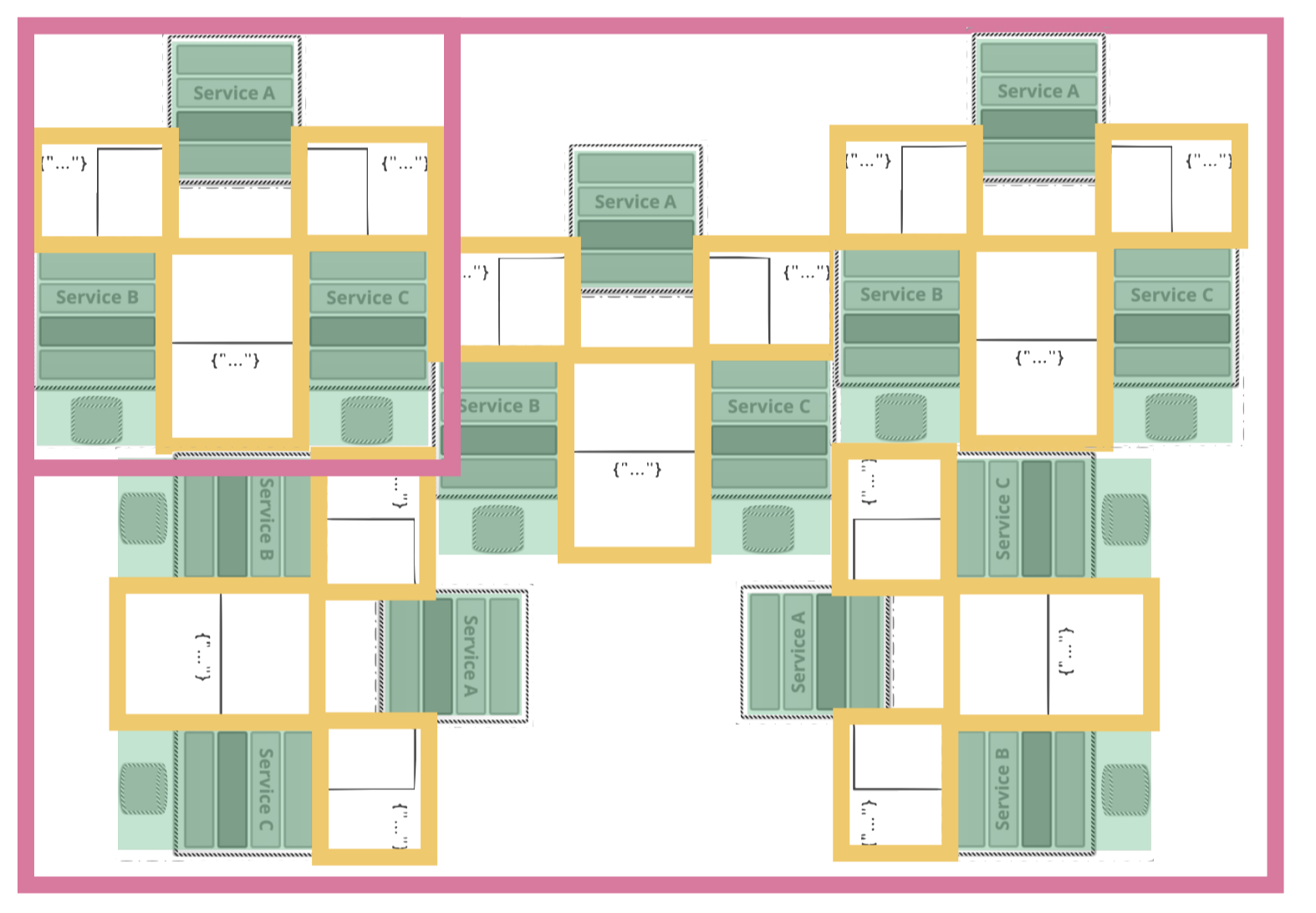
This is exactly where a major error occurs, which afterwards propagates through the entire software development cycle: When teams start with the first, small service, the business domain is often unclear. As a result, the system with the Services A, B and C is designed not as above but very different. Remember the three major feature of our examples? Giving just a quick thought about cutting the services, many teams will cut their architecture by those features:
One service handles the dashboard (and thus needs to know about user and encrypted messages, black circle). On service handles the inbox and displays messages (and thus need to know about the user, too, as well as the encrypted messages, yellow circle). The encryption holds/stores all the messages (blue circle).
That means, that the domains of “messages” and “users” is not contained to one service, but instead propagates through the system. And this is the critical point: if we now have a look at how to unit test those domains, the units spread across the services. We need two or three services to write the unit tests. Writing integration tests becomes incredibly complex – or more accurate: hell. Then its also no wonder that some people then tend to leave the integration tests aside and rather cover the entire system by end-to-end tests. The result will look similar to this:
In this situation, the tests are most likely very unstable: as already indicated in the picture there is no clear scheme of what to test where. The integration point of the domains are randomly somewhere in the services. It will be difficult to mock things. If all services are always needed to be available it usually leads to “flakiness” of tests in pre-production environments and it becomes very hard – if not impossible – to test on a local machine. For every fail of the end-to-end tests someone needs to check the error log, in order to find out if it is a “real” error or not. Let me repeat, this is gonna be incredibly complex – or more accurate: hell.
If we then start to automate the entire thing… (you remember: fast feedback and so on) we will end up with a workload that is way beyond what we experienced with the monolith. At this point of time it is perfectly reasonable to do a reality check, whether or not things became easier with the micro services. For all teams that chose this “approach” that I have worked with, we actually figured that we did not improve compared to a monolith. But realizing this is important and valuable:
If your finding is, that it got more complicated then better stop and think how to improve. Because otherwise, as soon as you start to build more and more services and scale your application, it will only get worse. Thus, do yourself a favor and spend a lot of time thinking about the domain split. It will be easier tot test – and scalable!
And at last, the biggest advice I can give to people – teams (!) – that start working with smaller services is to
“Test” in time.
What do I mean? The team needs to be involved early: Engage with the people designing the services. Talk to the business and understand the domains your are about to form in your services. And make sure that all people in your team have a clear understanding what you are doing and why you are doing this. This is the time where our role stretches far out of the testing area. This allows all of the former testers to grow out of the test manager role. We can make a real difference on the flexibility that our service landscape will provide to our business. Please make sure, that your team and your business benefits from the approach to micro service. Show them where the pitfalls are. And guide them.
To summarize:
Apply the testing pyramid. Make testing cheap and reliable. (as usual)
Automate everything (that you can). Each manual step is a real show blocker in a micro service environment.
Make it fast. Value the fast feedback from quick running pipelines. Be flexible.
Start in time. Get a clear picture about your business domains and how you think it is – should be – reflected it in your services.
The beauty is: once testing is easy and helpful its a real cool amplifier when you continue to build and improve your system. Have fun 🙂