As pointed out before: With continuous deployments the time from commit until live for any commit is the time you need until a bug can be fixed – at best! How can you push on this limit?
It usually requires that all people are aware of the code, the business, the infrastructure, the test and the pipeline. If each person has all this knowledge only then can you react quickly, without gathering the “right” people to ship a fix. In other words: you need a high performing and truly cross functional team. Let me emphasise this here once more: from our perspective there is a clear advantage for the quality of the product here: it is about reacting to (breaking) changes (even) faster.
What is the leverage you as quality advocate have? Talking about errors! Your team will do mistakes, this is good. We would be out of jobs if they did not. We are here to find them and to help the team to prevent them going forward. We are the experts on errors – in a way. So make sure that your team does not waste a mistake, but learns from it.
Idea for image originally from: http://ww2.kqed.org/mindshift
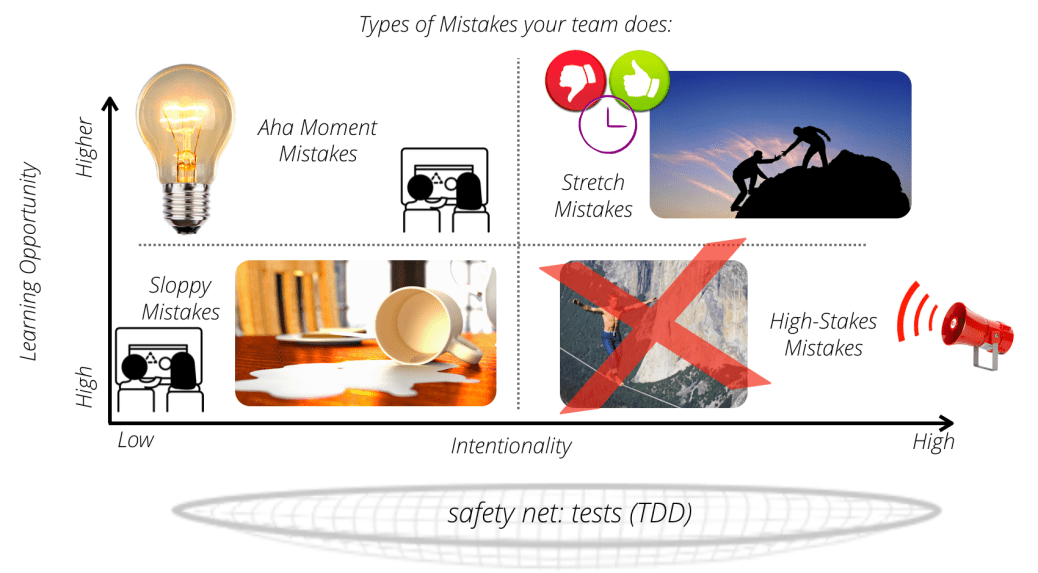
There are some mistakes that your team will be doing:
- Sloppy mistakes. This is the most common. There are probably a dozen of them in this very blog post. The human brain can only concentrate for about 10-15 minutes, until it needs a mini break. If we skip that break, we tend to do small mistakes.
A typical mitigation strategy for this is pairing of any two people. When one is not fully concentrated for a moment the other one most often is. - Aha-Moment Mistakes. This is when you encounter a (small) new learning by doing a mistake and finding out about it. It may happen if you understood something by reading or even much more so while explaining something.
We also mitigate this by pairing – ideally by different skilled developers. If a more senior person explains a lot to a more junior person both have a higher chance to do this error – and learn something from it right away. - Stretch Mistakes. In this scenario, we are quite away that we step out of our comfort zone. But when you need to or want to try something new you have to at least try, even if you already know that it’s more error prone than business as usual.
Our way around such requirements are so called “spikes”: small, time boxed stories that make sure we can trial-and-error in a save environment. Thus, the result of the spike can be a small prototype that is thrown away. A new service that got some basic things just working fine. Or a branch that is ready for an all-team-code review. - There are also some high-stakes mistakes. Those are equally risky as the stretch-mistakes but usually there is much less to gain. Those are not worth the effort. Prevent your team from doing these.
There are probably many more ways to categorise errors. There are also many more mitigation strategies, i.e. in our case we have the safety nets of our test-driven development. But differentiating the different types from one another is something that is typically quite easy for analysts who mostly work in the field of quality.
By encouraging your team to do errors (in a safe environment) you automatically get the basics right for a great error culture. And as soon as the impact of an error is reduced people will be much less afraid of doing errors. And if you are less afraid at work you are usually more creative. If a broken built is then nothing bad or painful (while still an urgent matter!) you will have a more relaxed, trustworthy and creative atmosphere. And guess what – in the end a lot less error happen in such an environment. Another boost for Quality!
The last fine tuning is to make sure your team has fun. Fun? Really? Yes.
Just like the point before: in an environment where people like to come to work, where they are happy to communicate and interact, where it’s fun to get work done, people will also be more focused and more passionate about what they do. As a result, they will do less errors with smaller impact. The ultimate boost for Quality!









