Once the process helps us to focus on fewer things and enables us to collaborate and test as a team, I as a “tester” will have more time. And I should spend that time where the product is actually baked: I should get more involved with the developers.
Many QAs are a bit hesitant to move somewhere close to the actual application code. But they shouldn’t be: our main contribution is not that we can code. There are other people who are much more specialised in. We call them developer. They are much better coders. And as such, much better suited to write automated tests. What is then left for a QA?
We bring very strong analytical skills. One of them can analyse all tests on all levels from a strategic point of view. What is the share of unit- integration and end-to-end tests? Where do we cover what business logic, where do we have gaps in our test coverage.
Many QAs who specialize in Front-End-Test-Automation write lots and lots of End-To-End / User-Journey tests. These tests are typically the most flaky, hard to maintain and cost intensive tests you can imagine. Hence, we usually advocate to add as few of them as late as possible.
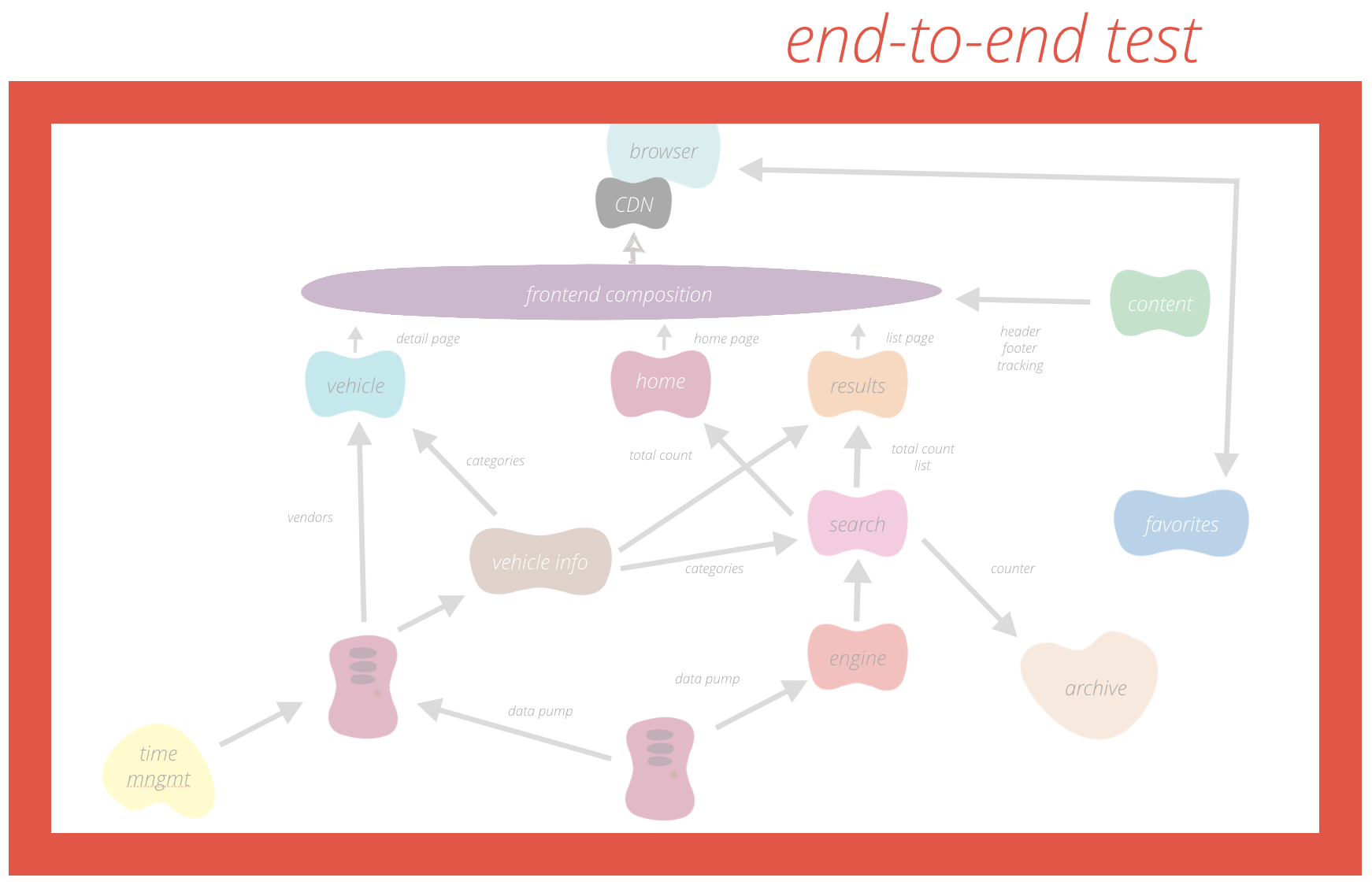
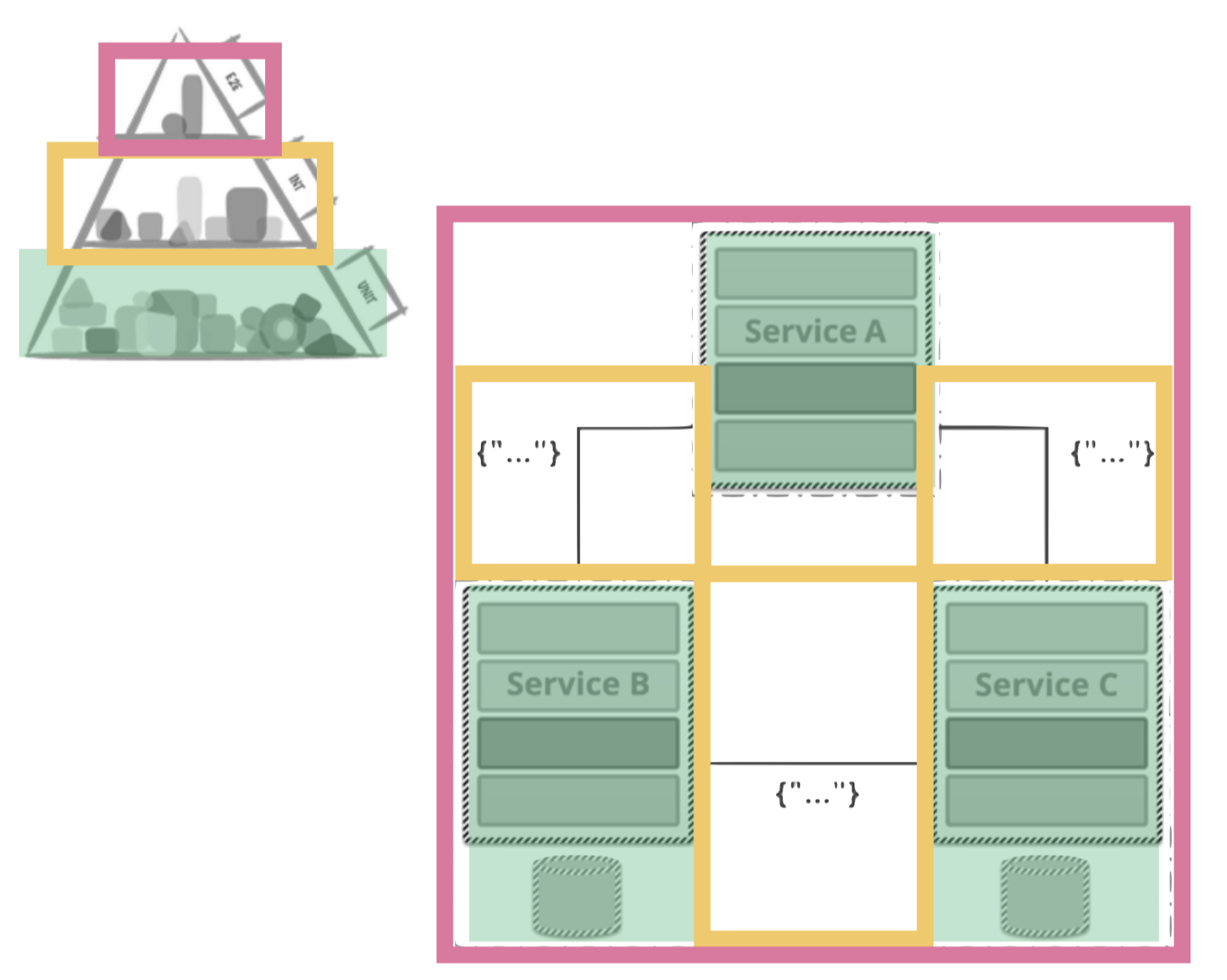
Instead QAs should aim to understand the big picture of the system architecture: what services do we have? How are they connected? How are they split? Does each service have a distinct capability? If so what is it and how does it relate to you business?
Once you figured that out you can assess how to test each of these services or domains in your service independently. If this works have a look at the communication between the domains and ensure this. If all of this is covered you may want to add a slight hint of an end-to-end test on top.
Obviously, the second approach is much more difficult – but that is what you are for and what you contribute in the team? You are the one to keep the big picture and consult your team members where to add what test in what way. What is the key assertion in a given test case? What is the right level for it? With a strong coder and your analytical abilities in testing you can ensure that things are working while they are implemented. That does not only improve quality early on, it also significantly decreases the time you need to spend testing (and reporting defects) afterwards.
Still, some defects will be released. No matter how much money you invest, there is no way to ensure bug free software at all (even if you are the NASA and spend more than 320 Million $ on a project). The second thing you can figure out with your dev team is how to identify and catch them. With the lean process (see above) that you established you can be sure to ship a potential fix very fast. The way to detect them is a helpful monitoring setup. This involves to visualise the amount of errors, as much as server/database request (and possibly a deviation to 24hours before). If you go to real professional levels you want to think about anomaly detection so that your system can notify you on its own once something is off.
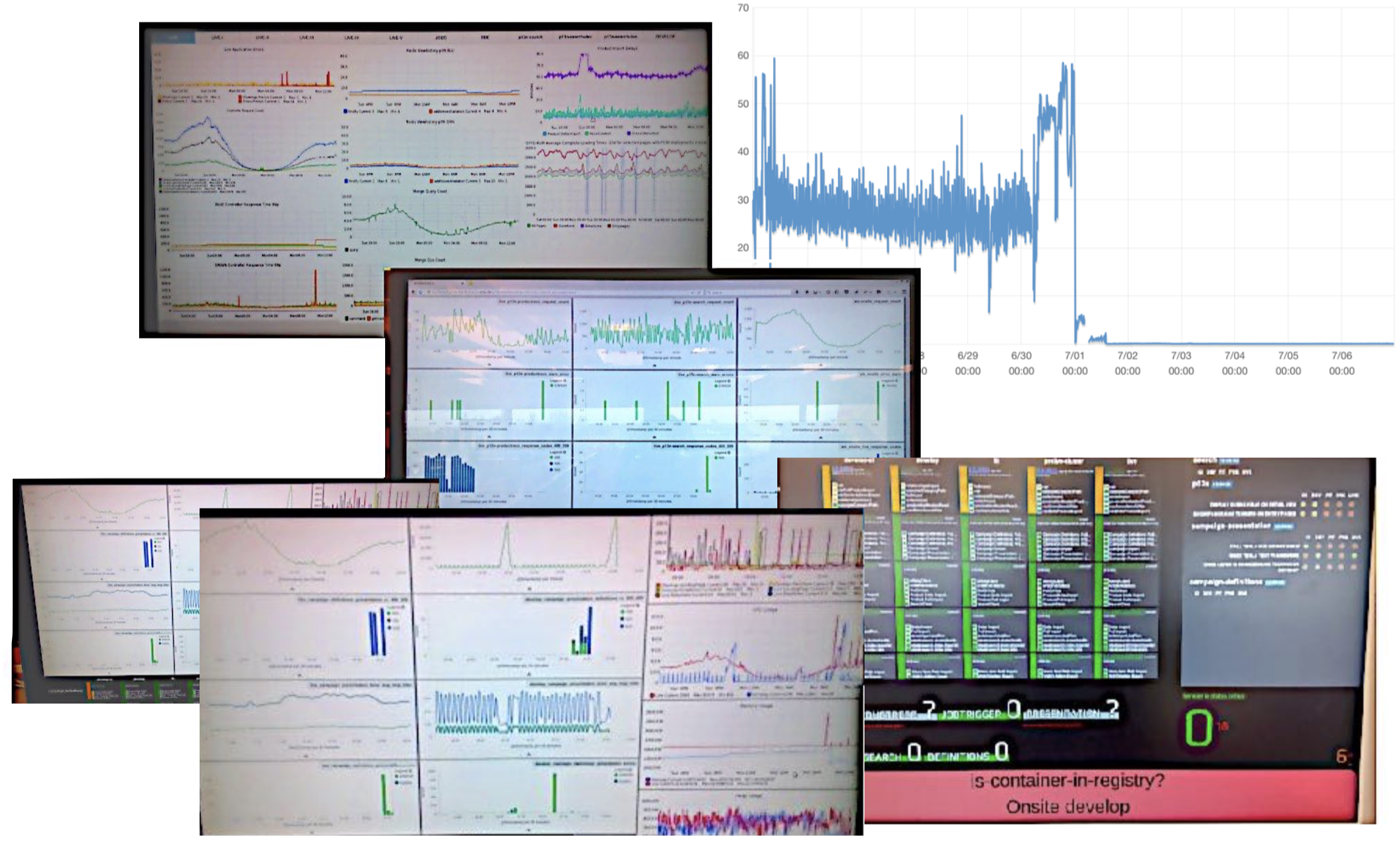
The last open question is how to react to breaking changes that you may have accidentally released to production. We are running a two fold strategy here. We try to minimize our time-to-market for bug fixes and mitigate risks of other larger issues with feature toggles. Let me go into some details:
Usually, in a classic release management process you have a plan how to do your releases and if there are major problems afterwards you execute a predefined rollback. If this is – for one reason or the other – not possible there is usually a hot-fix-release-branch-deploy process defined by someone somewhere. Here is the problem: If you need a hot fix then your team is probably already on fire. In this very moment you need to follow a process that most people are unfamiliar with which usually bypasses a lot of security measures you have previously established in your release cycle. That is quite a bad habit concerning the production problems one has in this very moment.
Our goal is to make the fasted possible release process our standard process. Thus we drive our teams to deploy every single commit to production. That also means that every commit has to be shippable – with enough tests to make sure our product is still working. This is baking quality in already!

Still, things will break. But with a quick way to react and deploy a fix we do not even need rollback strategies any more. But being able to deploy a hot fix very quickly implies that you can also quickly analyse the root cause. But that is not always true. If you know what commit was faulty you can of course deploy a revert. But sometimes a new feature in it’s complexity across stories and commits is just not working right. Thus, we work a lot with feature toggles, making sure that all new functionalities are toggled off in production. We also make sure that we can toggle those features independent of deployments. Thus, we decouple the technical risk of a deploy with the business risk of a feature toggle. This reduces our needs for reverts by about 90% and most deployments run automatically and without problems. Every few days a new feature is toggled on. People are then usually more aware of the situation and monitor the apps behaviour more closely (at least they should). Problems can then be identified and either quickly be fixed with a tiny commit or, if you encounter major blockers, you toggle the feature off again.
In conclusion, we have way fewer way less troublesome releases, while we can activate new features in a very controlled way. Thus, we do not only deliver value fast, we also achieve higher quality at the same time. However, a very experienced and disciplined team is needed to work on such a high level of quality commit by commit.