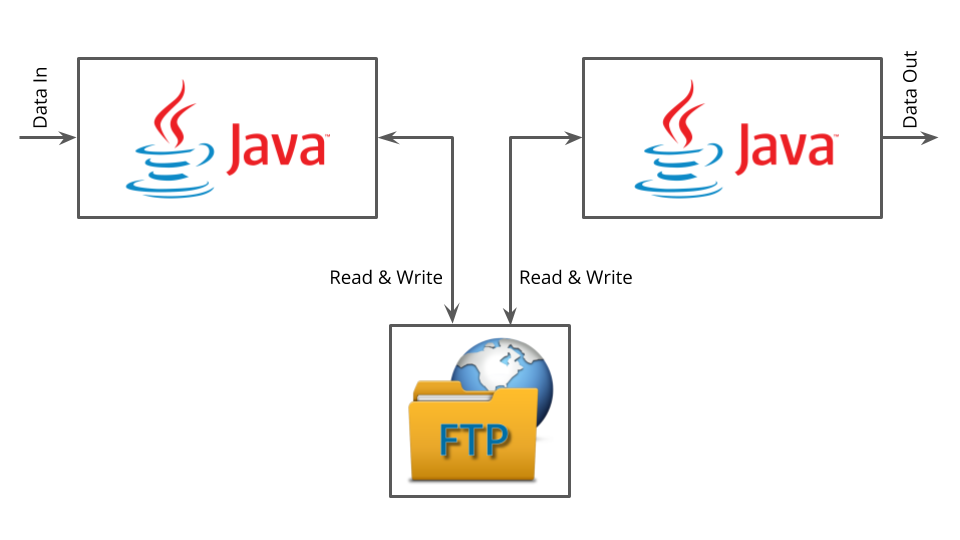
Since the 90s we know that Service Integrations via a shared file storage should be avoided. The system cannot be tested very well, debugging is hard and data not trustworthy as it’s manipulated by many sources.
Surprisingly, what we QAs of ThoughtWorks have observed in different teams with different clients over the past few months is a very strong tendency to service integrations via S3 buckets in Amazon Web Services (AWS). Many people (e.g. while Inceptions at the beginning of a project) that were working for our clients for many years actually suggested to read from / write to existing buckets. The main reason for those buckets to be widely used and accepted throughout the organizations were the data science projects that were starting or even already established in the companies.

Hence, the justifications we heard for such an integration between services was along the lines of “the data is there anyways” and/or “the data scientist will also need this data”. But being a data-centric or even a data-driven company should not compromise the way the integrations are built on the technical side. Doing “Data Science” does not require anti-patterns in architecture.
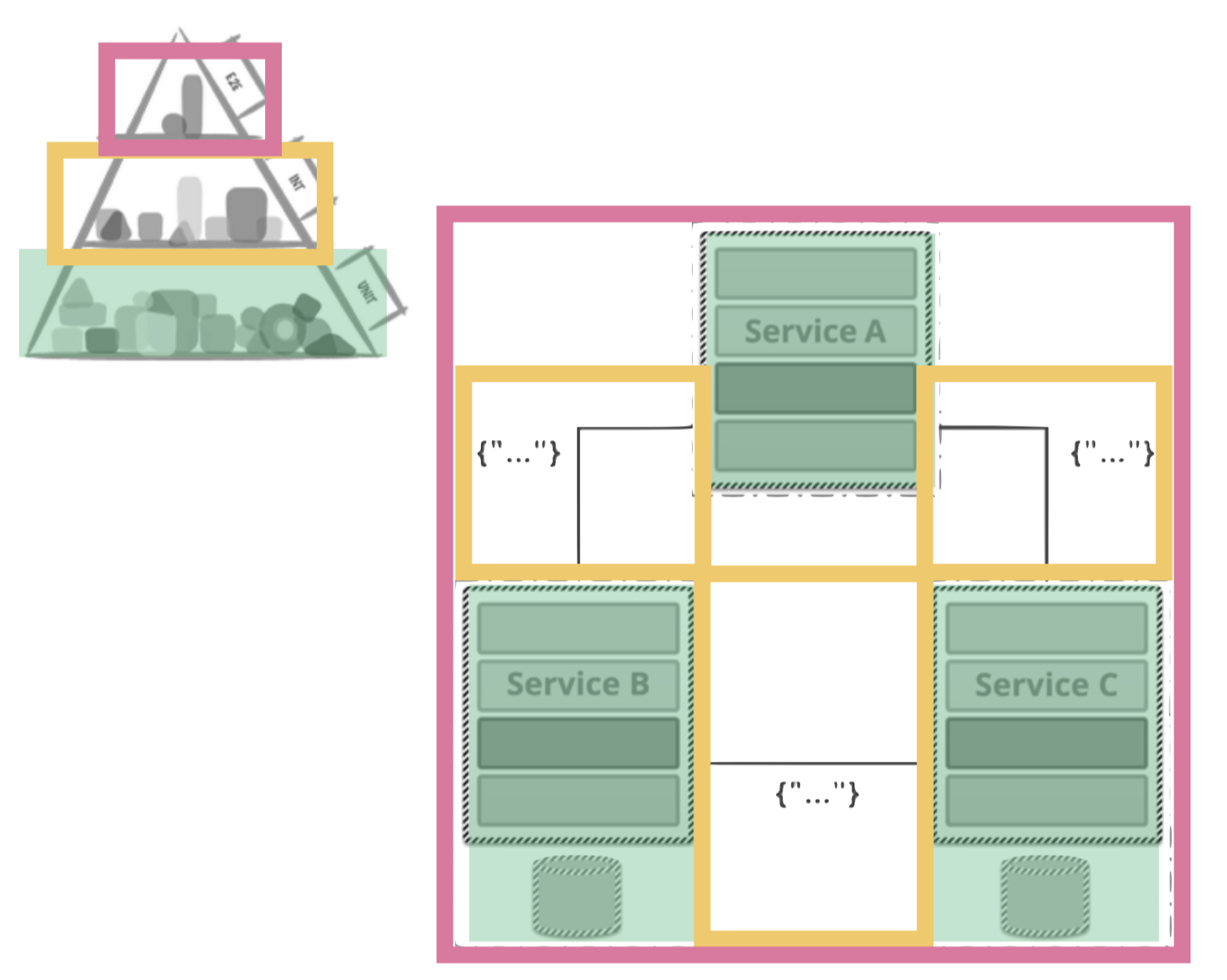
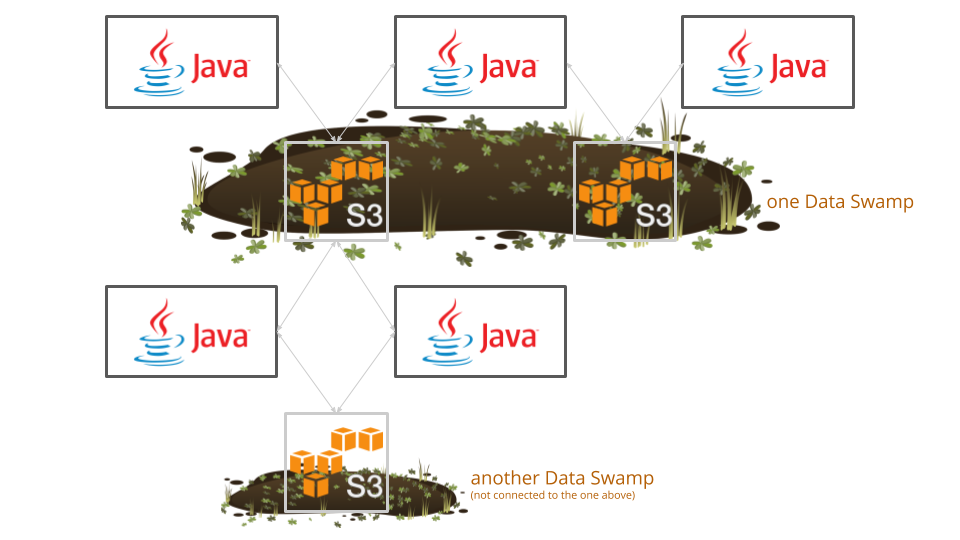
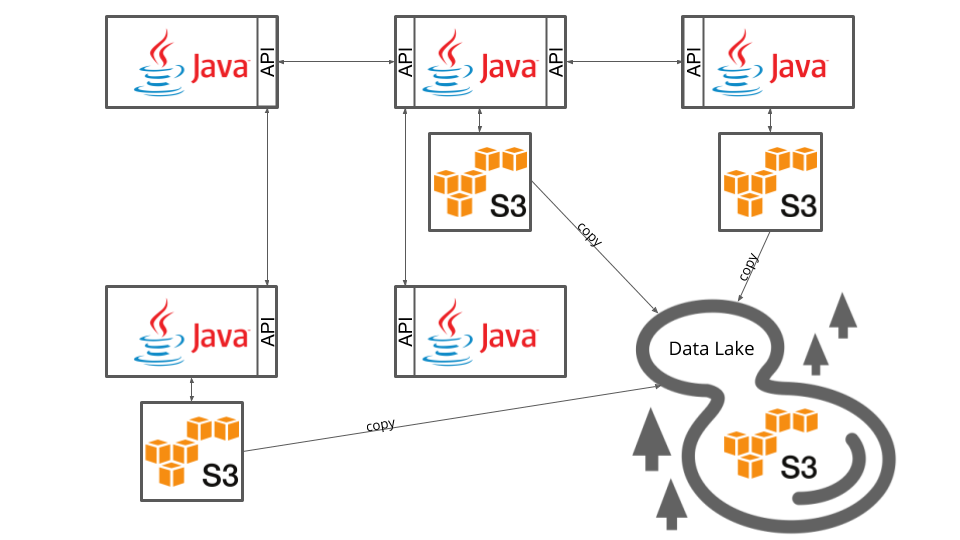
Also, we believe that this setup makes it actually more difficult to do accurate data science. No one could point us to a resource that helped to get an overview of what data is stored where. It’s unclear which data is used for what. Even worse, it’s not always possible to connect any two data stores in the data analysis. If we think of more than a couple of services, the integrations via S3 buckets looks like in the following diagram:

All of those services integrate via some S3 buckets. Those buckets are distributed throughout the architecture. Most of them already have old data but no one is really sure if it’s old data or still used as they have multiple read & write accesses and there is no way to keep an overview. This results in the current big data swamps we are working with. Mind the plural: swamps. Also, we don’t see them as clean lakes. Those buckets are sometimes not connected at all and the data is a pile of mud. This is what we reference to as a “data swamp”:
As QAs, we like to have clean integrations that can easily be tested and a clean flow of data through the system that enables debugging. It does not necessarily need to be predictive for big data, but an understanding of what type of data is flowing from Service A to Service B would undoubtedly be helpful. It is very hard to write integration- or maintainable end-to-end tests for those kinds of architectures with integrations of that kind. That is obviously one of the main motivations for us QAs to look more into this issue.
We advocate for a clean data storage for the data engineers and in our role we are actually in a good spot to do this: QAs typically care more than other people about Cross Functional Requirements (CFR). Storing masses of data in a proper system is as much a valid CFR as looking out for security, performance or e.g. usability.
Hence, in the last weeks we started discussing and we are wondering where this (quite enthusiastic!) buy-in for old anti-patterns is coming from. We are trying to understand more of the root causes of this type of architecture (besides doing “data science”). Does it come down to the typical “it’s quick to develop”, “we all understand the technology” or “we did not know what else to use”?
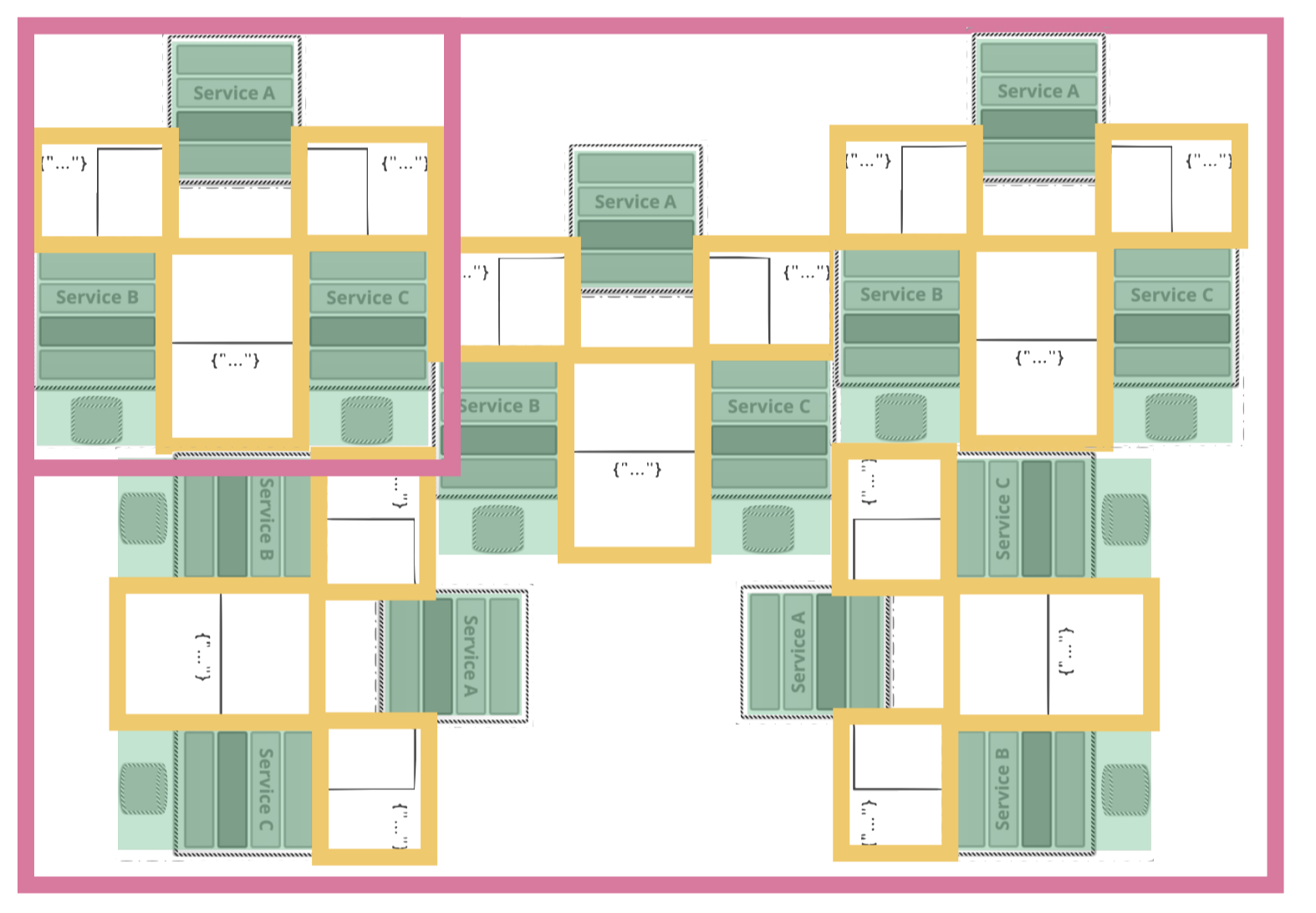
A more sustainable approach would obviously be to enable services to directly communicate with each other and not via shared file storage. That would allow any client to have stateless services that each store just the information they need.

That would allow us to build a more scalable system. It would allow us to test the integration between services much better – or at all for that matter! It does not necessarily all be via well defined APIs in synchronous calls. When one providing service has many consumers which only need new information at some point of time or if you have synchronous calls are cascading all through your system you may want to use something like the AWS simple notification service (SNS) instead (or Kafka to not just talk amazon here or rabbitmq or…). But any separation that is more structured will enable a company to actually scale faster.
But implementing APIs alone won’t do the trick. This suggestion for improvement has the base assumption of well split domains. I explained this in detail in this blog post.
Once you build a more structured architecture and have clean integrations, not only the future development of this application will benefit, there will also be a huge improvement for the the data scientists. When each service stores the relevant data on its own one can “simply copy”¹ the data and “do” any science on it. In one single place.² That would allow the data people to work on their own without the need of product teams building reports and data pipelines.
Footnotes:
- “simply copying” the data may also involve some queues/messages. It should not be a local bash script that is literally copying. For static data analysis you won’t need real-time data anyways, in this case it’s fine if you need some minutes to aggregate, process and store the data.
- “in one single place” may actually be different data stores: one for public information (like flight dates), one for not public information (like usernames/user identifiers) and yet another one for information that even most people of a company should not have (like financial data or user passwords).